
作者 | 王启隆 责编 | 梦依丹
我们都看过那些视频。一只灵巧的机械臂,用一种近乎优雅的姿态,为你倒一杯咖啡,叠一件衣服,甚至做一份素食三明治。视频里的机器人往往动作流畅,目的明确,每一次看到,我们都会忍不住惊叹,那个通用机器人帮我们处理琐碎家务的未来,似乎就在眼前。
但每次惊叹过后,一个问题总会悄悄浮现:然后呢?
这个完美的演示,能在我们家里的厨房复现吗?如果洗衣机的品牌、操作按钮都不一样,它还知道怎么使用吗?如果我家的 T 恤比视频里的更软、更薄,它还能叠得那么整齐吗?当一个团队宣称它的模型成功率高达 95% 时,我们更是无从知晓这个数字背后的真实场景——是由熟悉机器人脾性的工程师精心布置,还是在一个充满随机性的真实环境中独立完成?
我们不缺机智的算法,也不缺看起来很酷的演示视频。我们缺的是一把公认的、可靠的尺子。
整个领域似乎都在呼唤一个东西。一个不属于任何单一团队,中立、开放的第三方“试炼场”。一个地方,无论你是来自顶尖高校,还是一个初创公司,都必须在一样的规则下,面对一样的难题。在这里,没有精心设计的“甜蜜点”,只有混乱而真实的物理世界。在这里,所有的模型都必须卸下光环,接受最严苛的检验,让数据本身说话。
这个地方,将成为具身智能的“真实考场”。
最近,一个由 Dexmal 原力灵机联合 Hugging Face 共同发起的项目,似乎正是在尝试构建这样一个“考场”。它叫 RoboChallenge,一个听起来就充满挑战意味的名字。它没有发布又一个炫技视频,而是把全部精力都投入到了定义“考卷”和“考场规则”这些最基础、最困难,也最重大的工作上,尝试为这个喧嚣的领域,建立一套严格、透明且可信的度量衡。

公平的悖论
在真实世界里测试机器人,听起来简单,做起来却充满了陷阱。最大的一个陷阱,就是“人”。
想象一下,一个测试任务是让机器人把桌上的一个盒子放进柜子里。很简单,对吧?但结果可能天差地别,而这差异的根源,可能仅仅是由于摆放盒子的测试员不同。
RoboChallenge的团队在一篇报告里提到了一个超级有意思的观察,他们把测试员分成了三类:经验丰富的测试员、一无所知的测试员,和“自适应”的测试员。
经验丰富的测试员,就是那些收集训练数据的人。他们超级清楚这个机器人模型“喜爱”盒子摆在哪个位置,哪个角度。为了让结果尽可能地“好”,他们会下意识地把盒子放在那些模型最容易成功的地方。这当然是人之常情,但它污染了测试的公正性。
一无所知的测试员,是完全的新手。他们只是按照指令把盒子放在桌上。听起来很公平?但他们的行为充满了随机性。可能他今天心情好,把盒子摆得特别正。明天他累了,随手一扔,盒子是斜的。这种巨大的随机性,会让测试结果像坐过山车,今天成功率 100%,明天可能就是 0。这样的结果,我们能信任吗?
最有趣的是第三种,“自适应”的测试员。他们一般就是算法的作者。他们太想证明自己的模型有多出色了。在一次次测试中,他们会像一个精明的赌徒,不断寻找牌桌上的规律。他们会发现,只要盒子摆放在桌子左上角那个特定的“甜蜜点”,机器人的成功率就会奇迹般地飙升。于是,在后续的测试中,他们会有意无意地,把盒子一次次地放在那个被验证过的“甜蜜点”附近。

这听起来有点像作弊,但更多的是一种人性的自然流露:只要有人类参与,绝对的客观几乎是不可能的。人类的意图、经验、甚至潜意识,都会像幽灵一样笼罩在测试场上空,让所谓的“成功率”变成一个可以被操纵的数字。
这个问题不解决,任何真机测试都像建立在流沙之上。我们看到的可能不是算法的真实能力,而是测试员“导演”能力的比拼。
RoboChallenge给出的解决方案,简单而巧妙,甚至可以说有点“笨”。他们创新性地提出了一种叫做“视觉输入匹配”的方法。
在测试开始前,系统会从海量的演示数据中,随机抽取一帧初始状态的图像。这张图像会像一个半透明的“幽灵”一样,叠加在测试员眼前的实时监控画面上。测试员的任务,不再是“把盒子放在桌上”,而是变成了一个类似“找不同”的游戏:动手调整桌上物体的姿态和位置,直到实时画面和那个半透明的“幽灵”图像完全重合。

这个方法,一举解决了之前提到的所有问题。
它消除了经验带来的偏见。测试员不再需要知道模型的“喜好”,他只需要对齐图像。他的经验在这里毫无用武之地。
它也消除了巨大的随机性。每一次测试的初始状态,都被严格地“锚定”在了某个历史上的真实瞬间。这为不同模型、不同团队之间的比较,提供了一个坚实的基准。
更重大的是,它极大地降低了测试的门槛,让大规模的、可扩展的评测成为了可能。你不需要是一个经验丰富的机器人专家,你只需要有足够的耐心,去玩好这个“对齐”游戏。

机器人领域的“ImageNet时刻”
在计算机视觉领域,有一个名词是绕不开的:ImageNet。
在 ImageNet 出现之前,图像识别算法的进展,有点像一盘散沙。每个团队都在用自己的小数据集进行测试,大家公说公有理,婆说婆有理,谁也说服不了谁。
直到 2009 年,ImageNet 横空出世。它用一个包含了超过 1400 万张、覆盖 2 万多个类别的超大规模标注数据集,为整个领域提供了一个共同的靶子,一个公认的竞技场。
从那后来,每年的 ImageNet 大规模视觉识别挑战赛(ILSVRC),都成了计算机视觉领域的“奥林匹克”。所有顶尖的团队都来这里一决高下。正是在这个竞技场上,我们见证了 AlexNet 的石破天惊,见证了深度学习时代的开启。
RoboChallenge 正在做的,就是希望在更复杂的具身智能领域,复刻这个“ImageNet 时刻”。而他们推出的第一个基准测试集,叫做 Table30。

Table30,顾名思义,包含了 30 个在桌面上进行的操作任务。在过去,行业内的机器人竞赛或者评测,任务数量一般只有 3 到 5 个。这寥寥几个任务,更像是“特长展示”,团队可以针对性地进行优化,甚至“应试”。
而 30 个任务,意味着你必须思考“通用性”。
为了精准评估VLA算法的核心能力,RoboChallenge的首期“考场”搭建了由UR5、Franka Panda、COBOT Magic Aloha及ARX-5四类主流机型组成的标准化平台。现阶段,所有机械臂均配备夹爪,以建立一个清晰的评测基线,未来则会支持更多样的执行器类型。在感知方面,平台标配了多视角RGB与对齐深度信息的传感方案,以同时满足二维识别与三维推理的需求。这种克制而专注的设计,同样为未来留足了空间,例如计划在后续版本中集成力控或触觉传感器,以应对更复杂的任务。
这些任务听起来都是我们日常生活中的小事,但对机器人来说却是巨大的考验。列如,“叠洗碗布”(fold dishcloth),这涉及到对柔软、易变形物体的理解,可以说是目前所有机器人的噩梦。刚性物体,有明确的物理边界和可预测的运动轨迹。而一块布,你从不同的地方拎起来,它的形态是完全不同的,每一次互动都会产生无穷的变化。
又列如,“把薯条倒进盘子里”,这需要机器人理解容器和被包含物的关系,同时要准确控制倾倒的姿态和速度。再列如,“制作素食三明治”,这是一个多步骤、长序列的任务,机器人需要记住操作的顺序,先放生菜还是先放番茄,不能出错。
还有“双手协同”的任务,列如“将透明胶带粘到盒子上”,可能需要一只手固定盒子,另一只手拉伸和粘贴胶带。这极度考验模型的双手协调能力和对空间关系的理解。
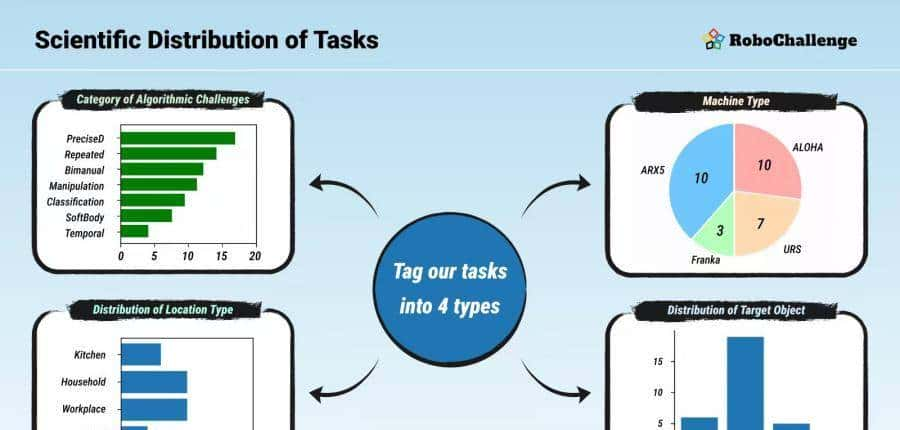
这些任务的设计,充满了巧思。它们不是随机挑选的,而是经过一个科学的分类学框架精心构建的。这个框架从四个维度来解构任务的难度:算法挑战、机器人类型、场景地点和目标物体。
通过这 30 个看似简单却暗藏玄机的任务,Table30 像一个精密的体检仪器,能全方位地扫描一个算法模型的“能力图谱”。它到底擅长精细操作,还是更懂双手协同?它是在处理软体物体时束手无策,还是在长期记忆上存在短板?所有的优缺点,都会在这个“考场”里被量化,被放大。
更有意思的是它的评分机制。传统的机器人测试,往往是“成王败寇”的二值化评估。任务完成了,就是 1,没完成,就是 0。这种方式过于粗暴。一个模型可能完成了 99% 的步骤,在最后一步由于一个微小的误差失败了,它得到的分数,和一个从一开始就完全不动弹的模型,是完全一样的。
Table30 创新性地引入了“进度评分”系统。它把一个复杂的任务,拆解成多个关键阶段。每完成一个阶段,模型就能获得相应的分数。列如“打开抽屉”这个任务,可以分解为“手臂到达抽屉附近”、“抓住把手”、“成功拉开”等步骤。即便最后一步失败了,模型也能由于它在前面步骤的努力而得到认可。
这个设计,让评估变得更加精细,更能体现出不同模型之间的“代差”。一个平庸的模型和一个优秀的模型之间的差距,不再是 0 和 1 的鸿沟,而是一条连续的、可以被准确度量的光谱。
而初步的测试结果,比任何语言都更有说服力,甚至堪称震撼。
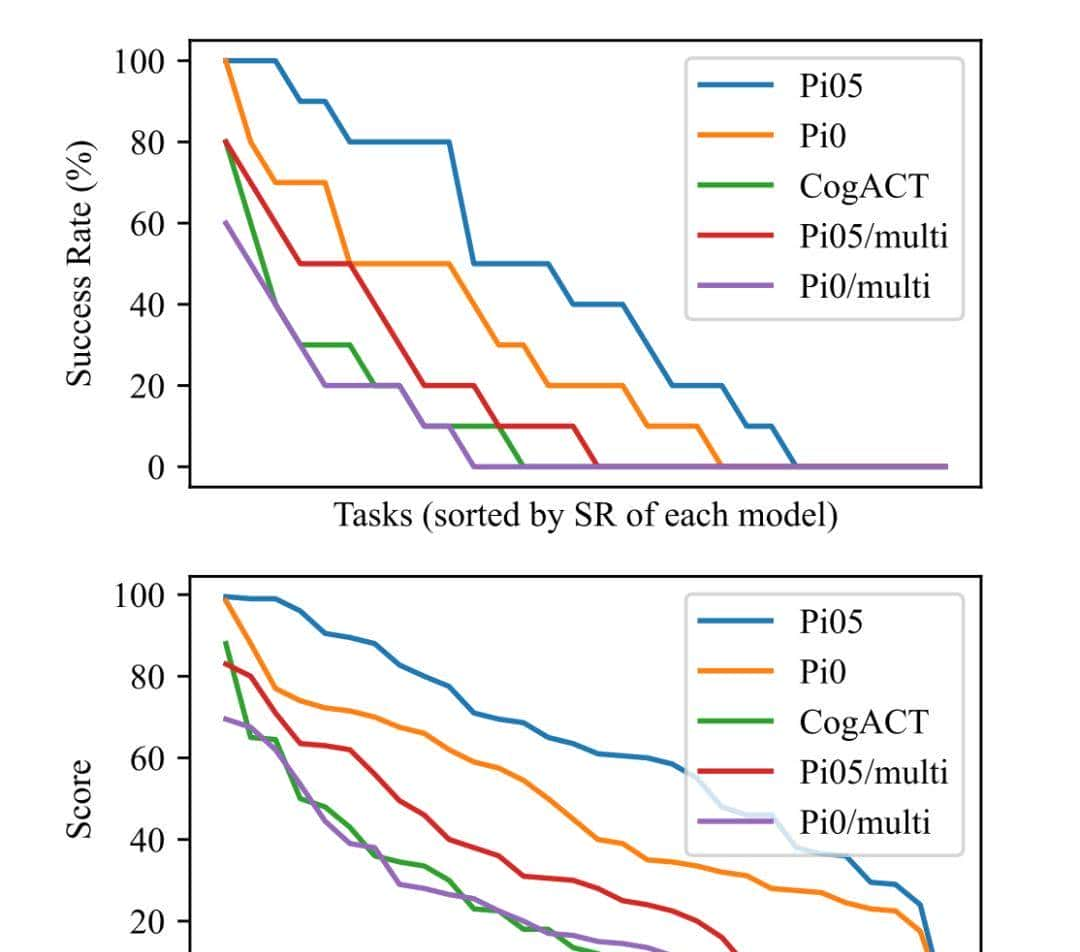
这张图清晰地揭示了两点。第一,是模型之间残酷的性能差距。以Pi05为代表的蓝色曲线,在成功率和得分上都全方位地、大幅度地领先于其他模型,这不是微小的改善,而是清晰的“代差”。这证明了Table30这把尺子的准确性——它能毫不含糊地告知你,谁是目前的领跑者。
但更重大、也更令人兴奋的是第二点:即便是最强的Pi05,其表现曲线也随着任务难度的增加而陡峭下滑,最终和所有模型一样归于零。这意味着,这个“考场”的难度是足够大的,它远未被任何现有模型“征服”。对于整个具身智能领域而言,这无疑是最好的消息:一个巨大的、充满挑战的、并且可以被清晰度量的创新空间,已经被打开了。
具身智能的评测一直徘徊在两个极端。
一端是大规模的仿真测试。在虚拟世界里,我们可以轻松模拟成千上万个场景,进行海量测试。但众所周知,仿真与现实之间存在着难以逾越的“Sim-to-Real Gap”,在模拟器里跑得再好的模型,到了真实物理世界也可能寸步难行。
另一端是小规模的真机测试。一些竞赛或研究中会用到真实机器人,但正如我们前面提到的,其任务量往往只有个位数。这种“管中窥豹”式的评测,无法系统性地衡量模型的泛化能力,更谈不上成为行业公认的基准。
这就形成了一个巨大的市场空白:行业内始终缺少一个兼具“真实物理世界”和“大规模、多任务”两大特性的公开评测平台。
RoboChallenge 的出现,正是为了填补这一空白。它不是对现有评测体系的微小改良,而是第一次,将“大规模、多任务”的评测标准,从仿真世界,真正带到了复杂的物理现实中。从这个意义上说,它是全球首个真正意义上的大规模多任务真机基准测试平台。而它要做的第一件事,就是像 ImageNet 为计算机视觉领域所做的那样,建立一个划时代的“考场”。

没有机器人,一样做实验
解决了公平性和规模化的问题,RoboChallenge 还想解决另一个更根本的问题:可及性。
机器人研究,在传统上是一个门槛极高的领域。它不仅需要深厚的算法知识,还需要昂贵的硬件设备、复杂的物理场地和专业的维护人员。一个顶尖的机器人实验室,投入动辄数百万甚至上千万。
这无形中将许多有才华但资源有限的研究者,挡在了门外。
许多时候,一个博士生想验证自己新想到的一个算法,可能需要排队等上好几个星期,才能轮到实验室里那台宝贵的机器人。这种资源上的瓶颈,极大地拖慢了整个领域的创新速度。
RoboChallenge 提出的解决方案,是革命性的,四个字就能概括:“远程机器人”。
他们的理念是,让全世界任何一个角落的研究者,只要有网络,就能连接到他们部署在中国的机器人集群上,进行真实的物理测试。真正实现“没有机器人,一样做实验”。
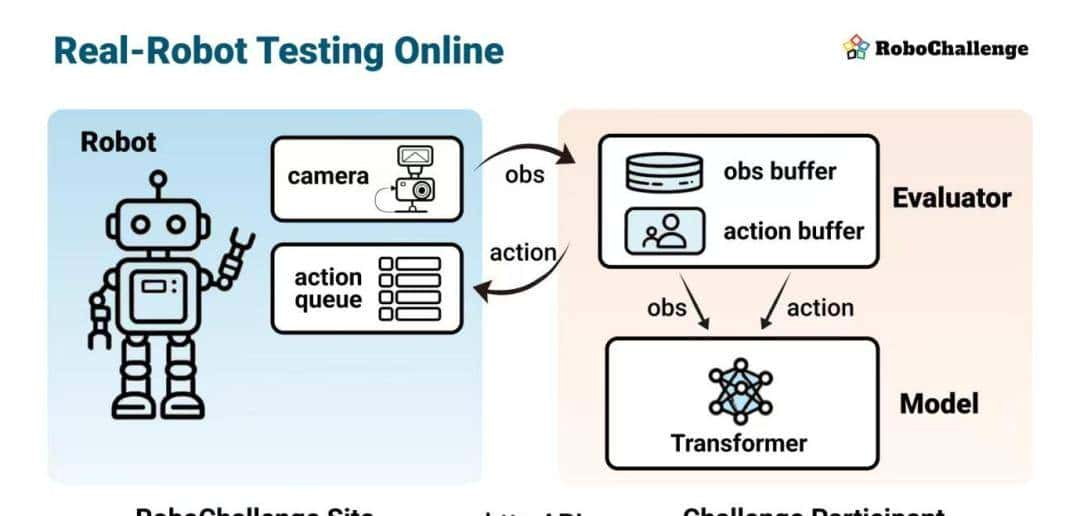
这背后是一套超级创新的系统架构。传统的远程测试,往往要求用户把自己的模型、代码、甚至整个软件环境打包成一个 Docker 镜像,上传到服务器上。这个过程超级繁琐,而且极易出错。不同版本的操作系统、不同的软件依赖库、不同的 GPU 驱动,任何一个微小的差异,都可能导致你的代码在别人的机器上跑不起来。
RoboChallenge 彻底抛弃了这种笨重的模式。他们选择了一种更轻、更灵活的“Model API Call”方式的变种。研究者不需要提交任何模型文件或代码。模型始终运行在用户自己的电脑上。
整个过程是这样的:用户的模型通过一个标准的 HTTP API,向 RoboChallenge 的服务器发送一个“请求”,说“我想看看目前机器人眼前是什么样子”。服务器就会立刻把机器人的多个摄像头捕捉到的、带有准确时间戳的图像和深度信息,传回给用户。用户的模型在本地进行计算,得出下一步应该执行的动作,然后再通过 API 把这个动作指令,发送到机器人的“动作队列”里。
这个双向、异步的控制机制,给了研究者极大的自由度。他们可以实现超级复杂的控制策略,列如根据网络延迟动态调整决策频率,或者同时运行多个模型进行集成决策。所有的计算都在本地,所有的控制都通过云端,整个过程就像是把机器人的“眼睛”和“手臂”延伸到了全球各地。
为了让这个体验更顺畅,他们还做了一个智能作业调度系统。用户提交测试请求后,系统会告知他,大致需要排队多久。这样,用户就可以先去忙别的事情,让自己的宝贵 GPU 去做别的计算。在测试即将开始前的几分钟,系统会发出通知,用户的程序再开始加载模型、预热 GPU,以最佳状态进入测试。
这种云端化的服务,在尝试拆掉那些横亘在机器人研究者面前的、由硬件和资源构筑的高墙,让创新的机会,能更公平地流向每一个有智慧的头脑。

从实验室智能,到现实世界智能
任何一个宏大的愿景,都需要一个脚踏实地的起点。Dexmal 原力灵机,这家成立不久却星光熠熠的公司,选择将 RoboChallenge 作为自己向世界发出的第一声问候。
这是一家很有意思的公司。它的创始团队,大多来自清华姚班,在中国顶尖的人工智能公司里身经百战。他们不是那种只会写论文的学者,而是经历过将算法技术转化为千万级产品的残酷洗礼的实干家。他们懂算法,懂硬件,更懂场景。这种“算法+硬件+场景”的复合基因,让他们在看待具身智能这个领域时,有了一种超级务实的视角。
而对于任何一个身处其中的研究者或工程师来说,最重大的问题永远是那个:“所以,我该怎么做?”
这恰恰是RoboChallenge最令人兴奋的地方。它不仅仅停留在理念的倡导,更是提供了一套清晰、完整的路径,让任何人都可以将自己的想法付诸实践。
整个过程,就像一场精心设计的寻宝游戏,目标就是挖掘出你模型的真实潜力。
一切都始于一个公开的数据集。你不需要自己费力去录制、去标注。RoboChallenge已经将所有任务的演示数据托管在Hugging Face上,你可以随时下载。这不是冰冷的合成数据,而是成千上万段真实机器人与物理世界互动的记录,充满了各种微小的、不可预测的细节。
拿到数据后,就是你施展才华的时刻。你可以用这些数据来微调你自己的模型,无论是专攻某项任务的“专才”,还是尝试通吃所有任务的“通才”。
当你觉得模型已经准备就绪时,就到了最关键的一步:通过API,让你的模型与远方的真实机器人“灵魂连接”。你的代码运行在你的电脑上,但它的每一个决策,都将通过网络,转化为物理世界里一次真实的抓取、一次精准的放置。这不再是模拟,这是你的算法在真实物理法则下的终极考验。
最后,你会看到结果。不是一个冷冰冰的成功或失败的标签,而是完整的测试录像和详细的机器日志。你可以像法医一样,逐帧分析你的模型在哪里犹豫,在哪里犯错,在哪里展现出超越预期的“灵性”。这本身就是一个无价的学习和迭代过程。
过去那种依赖于精美 PPT 和炫技短视频的时代或许正在过去。一个更加务实、更加透明、一切用真实数据说话的时代已经到来。
RoboChallenge的考场已经开放。目前,轮到你带上模型,亲自入场了。
-
官网:https://robochallenge.ai
-
论文:
https://robochallenge.ai/robochallenge_techreport.pdf -
GitHub:https://github.com/RoboChallenge/RoboChallengeInference
-
HuggingFace:https://huggingface.co/RoboChallengeAI
文末彩蛋
为了更深入地探讨其背后的思考与未来的蓝图,重磅直播已经为你准备就绪。
这不仅是一次简单的对谈,更是东西方具身智能领域两位顶级思想的碰撞。Dexmal原力灵机联合创始人兼CEO唐文斌,将与Hugging Face联合创始人兼首席科学家Thomas Wolf展开一场深度对话。他们将从开源精神出发,探讨其 如何成为点燃具身智能发展的核心引擎,并分享对行业未来的前瞻性思考。
RoboChallenge 全球首发同时还有两场相关主题的重磅直播,欢迎预约观看!


© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...







![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/2.jpg)



