示例背景:向量加法
目标是计算两个大数组(向量)
A
B
C
这个 GPU
__global__
// CUDA Kernel:在 GPU 上执行
__global__ void addVector(int *a, int *b, int *c, int n) {
// 计算全局唯一的线程 ID
int i = blockIdx.x * blockDim.x + threadIdx.x;
// 防止线程越界
if (i < n) {
c[i] = a[i] + b[i];
}
}代码讲解的核心在于
main
addVector
示例 1:传统内存模型 (Host 与 Device 分离)
核心思想: 正如您所说,Host (CPU) 和 Device (GPU) 内存地址不互通。我们必须手动分配(
h_
d_
cudaMemcpy
#include <iostream>
#include <stdio.h>
// (上面定义的 addVector Kernel 放在这里)
__global__ void addVector(int *a, int *b, int *c, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
c[i] = a[i] + b[i];
}
}
int main() {
int N = 10000;
size_t size = N * sizeof(int);
// 1. Host (CPU) 内存分配
// 'h_' 前缀代表 Host
int *h_a, *h_b, *h_c;
h_a = (int*)malloc(size);
h_b = (int*)malloc(size);
h_c = (int*)malloc(size);
// 2. Device (GPU) 内存分配
// 'd_' 前缀代表 Device
int *d_a, *d_b, *d_c;
cudaMalloc((void**)&d_a, size);
cudaMalloc((void**)&d_b, size);
cudaMalloc((void**)&d_c, size);
// 3. 在 Host (CPU) 上初始化数据
for (int i = 0; i < N; ++i) {
h_a[i] = i;
h_b[i] = i * 2;
}
// 4. 【手动拷贝】将数据从 Host 发送到 Device
// cudaMemcpyHostToDevice
cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice);
// 5. 在 GPU 上启动 Kernel
// 注意:Kernel 使用的是 Device 指针 (d_a, d_b, d_c)
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
addVector<<<blocksPerGrid, threadsPerBlock>>>(d_a, d_b, d_c, N);
// 6. 【手动拷贝】将结果从 Device 拷贝回 Host
// cudaMemcpyDeviceToHost
cudaMemcpy(h_c, d_c, size, cudaMemcpyDeviceToHost);
// 7. 在 Host (CPU) 上验证结果
// (这里 h_c 已经包含了来自 GPU 的结果)
bool success = true;
for (int i = 0; i < N; ++i) {
if (h_c[i] != (i + i * 2)) {
success = false;
break;
}
}
std::cout << "传统内存模型是否成功: " << (success ? "是" : "否") << std::endl;
// 8. 释放内存 (Host 和 Device 都要释放)
free(h_a);
free(h_b);
free(h_c);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}传统模型代码讲解
分离的指针: 我们需要维护两套指针:
h_a
d_a
手动数据流: 整个流程是手动的:
malloc
cudaMalloc
cudaMemcpy(..., cudaMemcpyHostToDevice)
Kernel<<<...>>>
cudaMemcpy(..., cudaMemcpyDeviceToHost)
free
cudaFree
复杂度: 这就是您提到的“需要手动将CPU数据发送给GPU”,代码繁琐且容易出错。
示例 2:统一内存模型 (Managed Memory)
核心思想: 使用
cudaMallocManaged()
#include <iostream>
#include <stdio.h>
// (上面定义的 addVector Kernel 放在这里,完全一样)
__global__ void addVector(int *a, int *b, int *c, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
c[i] = a[i] + b[i];
}
}
int main() {
int N = 10000;
size_t size = N * sizeof(int);
// 1. 【统一内存】分配
// 没有 'h_' 或 'd_' 之分
int *a, *b, *c;
cudaMallocManaged((void**)&a, size);
cudaMallocManaged((void**)&b, size);
cudaMallocManaged((void**)&c, size);
// 2. 在 Host (CPU) 上初始化数据
// CPU 直接访问这个 "托管" 指针
// (此时,数据页位于 Host RAM 中)
for (int i = 0; i < N; ++i) {
a[i] = i;
b[i] = i * 2;
}
// 3. 在 GPU 上启动 Kernel
// Kernel 使用【完全相同】的指针 (a, b, c)
// (当 GPU 访问时,CUDA 驱动自动将数据页从 Host 迁移到 Device)
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
addVector<<<blocksPerGrid, threadsPerBlock>>>(a, b, c, N);
// 4. 【重要】同步
// 因为 Kernel 是异步启动的,CPU 必须等待 GPU 完成
// 否则 CPU 可能会在 GPU 计算完成前就去读取结果
cudaDeviceSynchronize();
// 5. 在 Host (CPU) 上验证结果
// CPU 再次访问指针 'c'
// (CUDA 驱动自动将包含结果的数据页从 Device 迁回 Host)
bool success = true;
for (int i = 0; i < N; ++i) {
if (c[i] != (i + i * 2)) {
success = false;
break;
}
}
std::cout << "统一内存模型是否成功: " << (success ? "是" : "否") << std::endl;
// 6. 释放内存 (只需 cudaFree)
cudaFree(a);
cudaFree(b);
cudaFree(c);
return 0;
}统一内存代码讲解
单一指针: 我们只使用
cudaMallocManaged()
a
b
c
for
addVector
没有
cudaMemcpy
cudaMemcpy
自动迁移:
cudaMallocManaged
CPU 在
for
a
b
addVector<<<...>>>
a
b
CUDA 驱动捕获该错误,暂停 Kernel,自动将需要的数据页从 Host 迁移到 Device VRAM。
Kernel 恢复执行,在 GPU 上计算,并将结果写入
c
c
cudaDeviceSynchronize()
CPU 在
for
c
c
cudaDeviceSynchronize()
总结对比
| 特性 | 示例 1 (传统模型) | 示例 2 (统一内存) |
| 内存分配 | |
|
| 指针管理 | 两套指针 (e.g., |
一套指针 (e.g., |
| 数据拷贝 | 必须手动 ( |
自动迁移 (无需 |
| 编程复杂度 | 高,繁琐,易错 | 低,简洁,直观 |
| 同步 | |
必须显式 ( |
| 性能 | 手动优化时通常性能最高 | 编程简单,但自动迁移有开销 |
cudamallochost和malloc有什么区别?
它们都在 Host (CPU) 内存中分配,但
malloc
cudaMallocHost
这个“锁页”的特性,使得 CPU 和 GPU 之间的数据传输效率 产生巨大差异。
详细对比
| 特性 | malloc (标准 C 函数) | cudaMallocHost (CUDA API) |
| 分配位置 | Host (CPU) 内存 | Host (CPU) 内存 |
| 内存类型 | 可分页 (Pageable) | 锁页 (Pinned / Non-Pageable) |
| OS 行为 | 操作系统 (OS) 可以在物理内存不足时,将其交换 (Swap) 到磁盘(虚拟内存) | 操作系统 (OS) 不可以将其交换到磁盘。它被“钉”在物理 RAM 中。 |
| GPU 传输 | 慢 | 快 (通常是 |
| 异步拷贝 | 不支持 真正的异步 | 支持 (与 |
| 资源开销 | 常规、廉价 | 昂贵、稀缺 |
| 释放函数 | |
|
为什么
cudaMallocHost
cudaMallocHost
这才是这个问题的核心。
1. “锁页” 保证了物理地址
malloc
malloc
cudaMallocHost
cudaMallocHost
2. GPU 的 DMA 限制
GPU 使用一个称为 DMA (Direct Memory Access) 的引擎来在 Host 和 Device 之间传输数据。这个 DMA 引擎需要知道数据的物理地址。
当您使用
malloc
cudaMemcpy
GPU (的 DMA 引擎) 无法直接访问这块“可分页”内存,因为它不知道这块内存此刻是否在物理 RAM 中,还是已经被换到了硬盘上。
因此,CUDA 驱动程序必须首先在内部创建一个临时的锁页缓冲区 (Staging Buffer)。
然后,驱动程序先将您的
malloc
最后,DMA 引擎再从这个临时的锁页缓冲区 (GPU 传输) 拷贝到 GPU 显存。
这是一个两次拷贝的过程,效率很低。
当您使用
cudaMallocHost
由于这块内存保证在物理 RAM 中,并且其物理地址是固定的。
CUDA 驱动程序可以直接告诉 DMA 引擎:“去这个物理地址取数据”。
DMA 引擎直接将数据从您的
cudaMallocHost
这是一个一次传输的过程,速度快得多。
3. 启用真正的异步传输 (
cudaMemcpyAsync
cudaMemcpyAsync
cudaMemcpy
cudaMemcpyAsync
cudaMemcpyAsync
cudaMallocHost
总结
malloc
cudaMalloc
cudaMallocHost
malloc
cudaMalloc
最佳实践: 如果您的程序中 CPU 和 GPU 之间的数据传输是瓶颈,那么请将您用于
cudaMemcpy
h_
malloc
cudaMallocHost
cudaFreeHost
编写一个完整的 CUDA C++ (
.cu
这个测试将做以下事情:
分配一块可分页 (Pageable) 内存 (使用
malloc
分配一块锁页 (Pinned) 内存 (使用
cudaMallocHost
分配一块设备 (Device) 内存 (使用
cudaMalloc
使用 CUDA Events 精确计时,分别测试两种 Host 内存与 Device 内存之间的拷贝速度(上传 H2D 和下载 D2H)。
计算并报告带宽 (GiB/s)。
完整代码 (
test_bandwidth.cu
test_bandwidth.cu
#include <iostream>
#include <stdlib.h> // For malloc/free
#include <cuda_runtime.h>
#include <stdio.h>
// --- CUDA 错误检查宏 ---
// (这对于调试至关重要)
#define checkCudaErrors(call)
do {
cudaError_t err = call;
if (err != cudaSuccess) {
printf("CUDA Error at %s line %d: %s
",
__FILE__, __LINE__, cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
} while (0)
int main() {
// --- 1. 配置 ---
const int DATA_MB = 512;
const size_t size_bytes = (size_t)DATA_MB * 1024 * 1024;
const int REPETITIONS = 20; // 多次运行取平均值
// GiB (Gibibytes) 用于带宽计算
const double size_gib = (double)size_bytes / (1ULL << 30);
// --- 2. 内存分配 ---
char *h_pageable_mem; // Host (CPU) - 可分页
char *h_pinned_mem; // Host (CPU) - 锁页
char *d_device_mem; // Device (GPU)
// a) 可分页内存 (标准 malloc)
h_pageable_mem = (char*)malloc(size_bytes);
if (h_pageable_mem == NULL) {
printf("错误: 无法使用 malloc 分配 %d MB
", DATA_MB);
return 1;
}
// 'Touche' 内存,确保它被物理分配
for (size_t i = 0; i < size_bytes; ++i) h_pageable_mem[i] = (char)i;
// b) 锁页内存 (cudaMallocHost)
checkCudaErrors(cudaMallocHost((void**)&h_pinned_mem, size_bytes));
for (size_t i = 0; i < size_bytes; ++i) h_pinned_mem[i] = (char)i;
// c) 设备内存 (cudaMalloc)
checkCudaErrors(cudaMalloc((void**)&d_device_mem, size_bytes));
// --- 3. 计时器设置 ---
cudaEvent_t start, stop;
checkCudaErrors(cudaEventCreate(&start));
checkCudaErrors(cudaEventCreate(&stop));
float time_ms = 0;
float total_time_ms = 0;
double avg_time_ms = 0;
double bandwidth_gibs = 0;
printf("--- 性能测试开始 ---
");
printf("数据大小: %d MB (%f GiB)
", DATA_MB, size_gib);
printf("重复次数: %d
", REPETITIONS);
// --- 4. 预热 (Warm-up) ---
// 第一次 CUDA 调用通常有额外开销 (上下文创建等)
// 我们先运行一次拷贝,但不计时
printf("
正在预热...
");
checkCudaErrors(cudaMemcpy(d_device_mem, h_pinned_mem, size_bytes, cudaMemcpyHostToDevice));
checkCudaErrors(cudaDeviceSynchronize()); // 确保预热完成
// --- 5. 开始测试 ---
// === 测试 1: 可分页 (malloc) H2D (上传) ===
total_time_ms = 0;
for (int i = 0; i < REPETITIONS; ++i) {
checkCudaErrors(cudaEventRecord(start));
checkCudaErrors(cudaMemcpy(d_device_mem, h_pageable_mem, size_bytes, cudaMemcpyHostToDevice));
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop)); // 等待拷贝完成
checkCudaErrors(cudaEventElapsedTime(&time_ms, start, stop));
total_time_ms += time_ms;
}
avg_time_ms = total_time_ms / REPETITIONS;
bandwidth_gibs = size_gib / (avg_time_ms / 1000.0);
printf("[测试 1] 可分页 (malloc) Host -> Device: %.2f ms (%.2f GiB/s)
", avg_time_ms, bandwidth_gibs);
// === 测试 2: 锁页 (cudaMallocHost) H2D (上传) ===
total_time_ms = 0;
for (int i = 0; i < REPETITIONS; ++i) {
checkCudaErrors(cudaEventRecord(start));
checkCudaErrors(cudaMemcpy(d_device_mem, h_pinned_mem, size_bytes, cudaMemcpyHostToDevice));
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
checkCudaErrors(cudaEventElapsedTime(&time_ms, start, stop));
total_time_ms += time_ms;
}
avg_time_ms = total_time_ms / REPETITIONS;
bandwidth_gibs = size_gib / (avg_time_ms / 1000.0);
printf("[测试 2] 锁页 (Pinned) Host -> Device: %.2f ms (%.2f GiB/s)
", avg_time_ms, bandwidth_gibs);
printf("
");
// === 测试 3: 可分页 (malloc) D2H (下载) ===
total_time_ms = 0;
for (int i = 0; i < REPETITIONS; ++i) {
checkCudaErrors(cudaEventRecord(start));
checkCudaErrors(cudaMemcpy(h_pageable_mem, d_device_mem, size_bytes, cudaMemcpyDeviceToHost));
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
checkCudaErrors(cudaEventElapsedTime(&time_ms, start, stop));
total_time_ms += time_ms;
}
avg_time_ms = total_time_ms / REPETITIONS;
bandwidth_gibs = size_gib / (avg_time_ms / 1000.0);
printf("[测试 3] 可分页 (malloc) Device -> Host: %.2f ms (%.2f GiB/s)
", avg_time_ms, bandwidth_gibs);
// === 测试 4: 锁页 (cudaMallocHost) D2H (下载) ===
total_time_ms = 0;
for (int i = 0; i < REPETITIONS; ++i) {
checkCudaErrors(cudaEventRecord(start));
checkCudaErrors(cudaMemcpy(h_pinned_mem, d_device_mem, size_bytes, cudaMemcpyDeviceToHost));
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
checkCudaErrors(cudaEventElapsedTime(&time_ms, start, stop));
total_time_ms += time_ms;
}
avg_time_ms = total_time_ms / REPETITIONS;
bandwidth_gibs = size_gib / (avg_time_ms / 1000.0);
printf("[测试 4] 锁页 (Pinned) Device -> Host: %.2f ms (%.2f GiB/s)
", avg_time_ms, bandwidth_gibs);
// --- 6. 清理 ---
printf("
--- 测试完成, 清理内存 ---
");
checkCudaErrors(cudaEventDestroy(start));
checkCudaErrors(cudaEventDestroy(stop));
checkCudaErrors(cudaFree(d_device_mem));
checkCudaErrors(cudaFreeHost(h_pinned_mem));
free(h_pageable_mem);
return 0;
}
--- 性能测试开始 ---
数据大小: 5 MB (0.004883 GiB)
重复次数: 20
正在预热...
[测试 1] 可分页 (malloc) Host -> Device: 3.90 ms (1.25 GiB/s)
[测试 2] 锁页 (Pinned) Host -> Device: 3.52 ms (1.39 GiB/s)
[测试 3] 可分页 (malloc) Device -> Host: 3.63 ms (1.35 GiB/s)
[测试 4] 锁页 (Pinned) Device -> Host: 3.30 ms (1.48 GiB/s)
--- 测试完成, 清理内存 ---
--- 性能测试开始 ---
数据大小: 51 MB (0.049805 GiB)
重复次数: 20
正在预热...
[测试 1] 可分页 (malloc) Host -> Device: 39.05 ms (1.28 GiB/s)
[测试 2] 锁页 (Pinned) Host -> Device: 35.56 ms (1.40 GiB/s)
[测试 3] 可分页 (malloc) Device -> Host: 36.15 ms (1.38 GiB/s)
[测试 4] 锁页 (Pinned) Device -> Host: 32.85 ms (1.52 GiB/s)
--- 测试完成, 清理内存 ---
--- 性能测试开始 ---
数据大小: 512 MB (0.500000 GiB)
重复次数: 20
正在预热...
[测试 1] 可分页 (malloc) Host -> Device: 391.29 ms (1.28 GiB/s)
[测试 2] 锁页 (Pinned) Host -> Device: 355.41 ms (1.41 GiB/s)
[测试 3] 可分页 (malloc) Device -> Host: 361.83 ms (1.38 GiB/s)
[测试 4] 锁页 (Pinned) Device -> Host: 328.13 ms (1.52 GiB/s)
--- 测试完成, 清理内存 ---结论: 性能测试清晰地证明了我们之前的理论:
使用
malloc
malloc
使用
cudaMallocHost
重要提示: 虽然
cudaMallocHost
cudaMallocManaged
cudaMallocHost
cudaMallocManaged
隐式迁移 (Implicit Migration): 这是“便捷”模式。当 GPU 访问 CPU 上的数据时,系统自动暂停、迁移数据、再继续。这有开销。
显式预取 (Explicit Prefetching): 这是“性能”模式。我们使用
cudaMemPrefetchAsync()
测试将对比这两种模式与“黄金标准”——
cudaMallocHost
cudaMemcpy
#include <iostream>
#include <stdlib.h>
#include <cuda_runtime.h>
#include <stdio.h>
#include <chrono> // (FIX: 包含 CPU 计时器库)
// --- CUDA 错误检查宏 ---
#define checkCudaErrors(call)
do {
cudaError_t err = call;
if (err != cudaSuccess) {
printf("CUDA Error at %s line %d: %s
",
__FILE__, __LINE__, cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
} while (0)
// --- Kernel (与 v4 相同) ---
__global__ void simpleKernel(char *data, size_t n, unsigned long long* sum_out) {
__shared__ unsigned long long s_sum;
if (threadIdx.x == 0) s_sum = 0;
__syncthreads();
size_t i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
data[i] = data[i] + 1;
atomicAdd(&s_sum, (unsigned long long)data[i]);
}
__syncthreads();
if (threadIdx.x == 0) {
atomicAdd(sum_out, s_sum);
}
}
// --- CPU 函数 (与 v4 相同) ---
unsigned long long touchDataOnHost(char* data, size_t n) {
size_t step = 1024;
unsigned long long sum = 0;
for (size_t i = 0; i < n; i += step) {
data[i] = data[i] - 1;
sum += data[i];
}
return sum;
}
int main() {
// --- 1. 配置 ---
const int DATA_MB = 512;
const size_t size_bytes = (size_t)DATA_MB * 1024 * 1024;
const int REPETITIONS = 10;
const double size_gib = (double)size_bytes / (1ULL << 30);
int deviceId = 0;
checkCudaErrors(cudaSetDevice(deviceId));
// --- 2. 内存分配 ---
char *h_pinned_mem;
char *d_device_mem;
char *um_managed_mem;
unsigned long long *d_kernel_sum;
checkCudaErrors(cudaMallocHost((void**)&h_pinned_mem, size_bytes));
checkCudaErrors(cudaMalloc((void**)&d_device_mem, size_bytes));
checkCudaErrors(cudaMallocManaged((void**)&um_managed_mem, size_bytes));
checkCudaErrors(cudaMallocManaged((void**)&d_kernel_sum, sizeof(unsigned long long)));
// --- 3. 初始化数据 (在 CPU 上) ---
for (size_t i = 0; i < size_bytes; ++i) {
h_pinned_mem[i] = (char)i;
um_managed_mem[i] = (char)i;
}
// --- 4. 计时器设置 ---
cudaEvent_t start_gpu, stop_gpu; // (FIX: 只用于 GPU)
checkCudaErrors(cudaEventCreate(&start_gpu));
checkCudaErrors(cudaEventCreate(&stop_gpu));
float time_ms_gpu = 0;
double total_time_ms = 0;
double avg_time_ms = 0;
double bandwidth_gibs = 0;
unsigned long long dummy_sum = 0;
int threadsPerBlock = 256;
int blocksPerGrid = (size_bytes + threadsPerBlock - 1) / threadsPerBlock;
printf("--- 统一内存 (Managed) vs 锁页 (Pinned) 性能测试 ---
");
printf("--- (v5 - 修复 CPU 计时器问题) ---
");
printf("数据大小: %d MB (%f GiB)
", DATA_MB, size_gib);
printf("重复次数: %d
", REPETITIONS);
// --- 5. 预热 ---
printf("
正在预热...
");
checkCudaErrors(cudaMemcpy(d_device_mem, h_pinned_mem, size_bytes, cudaMemcpyHostToDevice));
*d_kernel_sum = 0;
simpleKernel << <blocksPerGrid, threadsPerBlock >> > (d_device_mem, size_bytes, d_kernel_sum);
checkCudaErrors(cudaDeviceSynchronize());
dummy_sum = touchDataOnHost(um_managed_mem, size_bytes);
printf("预热完成。 (CPU checksum: %llu)
", dummy_sum);
// --- H2D (上传) 带宽测试 ---
printf("--- H2D (上传) 带宽测试 ---
");
// === 测试 1: Pinned H2D (cudaMemcpy) [基准] ===
total_time_ms = 0;
for (int i = 0; i < REPETITIONS; ++i) {
checkCudaErrors(cudaEventRecord(start_gpu));
checkCudaErrors(cudaMemcpy(d_device_mem, h_pinned_mem, size_bytes, cudaMemcpyHostToDevice));
checkCudaErrors(cudaEventRecord(stop_gpu));
checkCudaErrors(cudaEventSynchronize(stop_gpu));
checkCudaErrors(cudaEventElapsedTime(&time_ms_gpu, start_gpu, stop_gpu));
total_time_ms += time_ms_gpu;
}
avg_time_ms = total_time_ms / REPETITIONS;
bandwidth_gibs = size_gib / (avg_time_ms / 1000.0);
printf("[Test 1] Pinned (cudaMemcpy): %.2f ms (%.2f GiB/s)
", avg_time_ms, bandwidth_gibs);
// === 测试 2: Managed H2D (Implicit Kernel) ===
total_time_ms = 0;
for (int i = 0; i < REPETITIONS; ++i) {
dummy_sum = touchDataOnHost(um_managed_mem, size_bytes);
*d_kernel_sum = 0;
checkCudaErrors(cudaEventRecord(start_gpu));
simpleKernel << <blocksPerGrid, threadsPerBlock >> > (um_managed_mem, size_bytes, d_kernel_sum);
checkCudaErrors(cudaEventRecord(stop_gpu));
checkCudaErrors(cudaEventSynchronize(stop_gpu));
checkCudaErrors(cudaEventElapsedTime(&time_ms_gpu, start_gpu, stop_gpu));
total_time_ms += time_ms_gpu;
}
printf("(Debug: CPU sum: %llu, GPU sum: %llu)
", dummy_sum, *d_kernel_sum);
avg_time_ms = total_time_ms / REPETITIONS;
bandwidth_gibs = size_gib / (avg_time_ms / 1000.0);
printf("[Test 2] Managed (Implicit Kernel): %.2f ms (%.2f GiB/s)*
", avg_time_ms, bandwidth_gibs);
printf("* (注意:Test 2 的时间包含了 Kernel 执行和迁移开销)
");
// --- D2H (下载) 带宽测试 ---
printf("--- D2H (下载) 带宽测试 ---
");
// === 测试 3: Pinned D2H (cudaMemcpy) [基准] ===
total_time_ms = 0;
for (int i = 0; i < REPETITIONS; ++i) {
checkCudaErrors(cudaEventRecord(start_gpu));
checkCudaErrors(cudaMemcpy(h_pinned_mem, d_device_mem, size_bytes, cudaMemcpyDeviceToHost));
checkCudaErrors(cudaEventRecord(stop_gpu));
checkCudaErrors(cudaEventSynchronize(stop_gpu));
checkCudaErrors(cudaEventElapsedTime(&time_ms_gpu, start_gpu, stop_gpu));
total_time_ms += time_ms_gpu;
}
avg_time_ms = total_time_ms / REPETITIONS;
bandwidth_gibs = size_gib / (avg_time_ms / 1000.0);
printf("[Test 3] Pinned (cudaMemcpy): %.2f ms (%.2f GiB/s)
", avg_time_ms, bandwidth_gibs);
// === 测试 4: Managed D2H (Implicit Faulting) ===
total_time_ms = 0;
for (int i = 0; i < REPETITIONS; ++i) {
*d_kernel_sum = 0;
simpleKernel << <blocksPerGrid, threadsPerBlock >> > (um_managed_mem, size_bytes, d_kernel_sum);
checkCudaErrors(cudaDeviceSynchronize()); // 确保数据在 GPU 上
// (FIX: 使用 C++ chrono 计时器)
auto start_cpu = std::chrono::high_resolution_clock::now();
dummy_sum = touchDataOnHost(um_managed_mem, size_bytes);
auto stop_cpu = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> time_ms_cpu = stop_cpu - start_cpu;
total_time_ms += time_ms_cpu.count();
}
printf("(Debug: CPU sum: %llu, GPU sum: %llu)
", dummy_sum, *d_kernel_sum);
avg_time_ms = total_time_ms / REPETITIONS;
bandwidth_gibs = size_gib / (avg_time_ms / 1000.0);
printf("[Test 4] Managed (Implicit CPU Access): %.2f ms (%.2f GiB/s)*
", avg_time_ms, bandwidth_gibs);
printf("* (注意:Test 4 的时间包含了 CPU 循环和迁移开销)
");
// --- 6. 清理 ---
printf("
--- 测试完成, 清理内存 ---
");
checkCudaErrors(cudaEventDestroy(start_gpu));
checkCudaErrors(cudaEventDestroy(stop_gpu));
checkCudaErrors(cudaFree(d_device_mem));
checkCudaErrors(cudaFreeHost(h_pinned_mem));
checkCudaErrors(cudaFree(um_managed_mem));
checkCudaErrors(cudaFree(d_kernel_sum));
return 0;
}
数据大小: 512 MB (0.500000 GiB)
重复次数: 10
正在预热...
预热完成。 (CPU checksum: 18446744073709027328)
--- H2D (上传) 带宽测试 ---
[Test 1] Pinned (cudaMemcpy): 365.59 ms (1.37 GiB/s)
(Debug: CPU sum: 18446744073708503040, GPU sum: 18446744073435348992)
[Test 2] Managed (Implicit Kernel): 259.63 ms (1.93 GiB/s)*
* (注意:Test 2 的时间包含了 Kernel 执行和迁移开销)
--- D2H (下载) 带宽测试 ---
[Test 3] Pinned (cudaMemcpy): 328.49 ms (1.52 GiB/s)
(Debug: CPU sum: 18446744073709027328, GPU sum: 18446744073430630400)
[Test 4] Managed (Implicit CPU Access): 3363.51 ms (0.15 GiB/s)*
* (注意:Test 4 的时间包含了 CPU 循环和迁移开销)
--- 测试完成, 清理内存 ---1. 关键发现:Test 4 (D2H 隐式迁移) 性能极差
[Test 4] Managed (Implicit CPU Access): 3363.51 ms (0.15 GiB/s)
分析: 这次计时器工作正常了,我们看到了真实的数据:耗时 3.36 秒,带宽仅为 0.15 GiB/s。
结论: 这完美地展示了我们之前讨论的“性能陷阱”。
您的
cudaMemcpy
您的隐式 CPU 访问 (Test 4) 速度是 0.15 GiB/s。
隐式 D2H 迁移比手动
cudaMemcpy
原因:
cudaMemcpy
✅ 核心结论 1: 永远不要让 CPU 直接访问一个刚被 GPU 使用过的
cudaMallocManaged
cudaMemcpy
cudaMemPrefetchAsync
gemini问题分析:
测试结果揭示了两个截然不同的问题:一个关于您的硬件,一个关于统一内存的性能陷阱。
1. 关键发现:Test 4 (D2H 隐式迁移) 性能极
[Test 4] Managed (Implicit CPU Access): 3219.38 ms (0.16 GiB/s)
分析: 计时器工作正常了,我们看到了真实的数据:耗时 3.2 秒,带宽仅为 0.16 GiB/s。
结论: 这完美地展示了我们之前讨论的“性能陷阱”。
您的
cudaMemcpy
您的隐式 CPU 访问 (Test 4) 速度是 0.16 GiB/s。
隐式 D2H 迁移(CPU 逐页拉取)比手动
cudaMemcpy
✅ 核心结论 1: 永远不要让 CPU 直接访问一个刚被 GPU 使用过的
cudaMallocManaged
2. 关键发现:Test 1 & 3 – 您的 RTX 2060S 硬件带宽极低
[Test 1] Pinned (cudaMemcpy H2D): 1.36 GiB/s
[Test 3] Pinned (cudaMemcpy D2H): 1.52 GiB/s
分析: 这是最关键的问题。您使用的是桌面版 RTX 2060 Super,它是一款 PCIe 3.0 x16 显卡。
应有速度: 它的
cudaMemcpy
您的实测速度: 只有 1.36 GiB/s。
✅ 核心结论 2: 您的 GPU 没有以全速 (PCIe 3.0 x16) 运行。它的运行速度大约只有其应有速度的 1/10。
这强烈表明您的 GPU 插在了主板上错误的 PCIe 插槽中,例如一个
x2
x4
x16
3. 令人惊讶的发现:Test 2 (H2D 隐式迁移) 在您的系统上获胜
[Test 1] Pinned (cudaMemcpy H2D): 1.36 GiB/s
[Test 2] Managed (Implicit Kernel H2D): 1.90 GiB/s
分析: 这是最有趣的结果。在您这个带宽严重受限(仅 1.36 GiB/s)的硬件上,由 Kernel 触发的自动 H2D 迁移 (1.90 GiB/s) 竟然比手动的
cudaMemcpy
结论: 这表明,在您这种特定的“慢速总线”硬件上,CUDA 驱动的“按需页面迁移”机制(GPU “拉” 数据)在调度总线方面,比手动的
cudaMemcpy
✅ 核心结论 3: 在您的当前硬件配置下,
cudaMallocManaged
行动方案
短期(基于当前结果):
上传 (H2D): 使用
cudaMallocManaged
下载 (D2H): 绝对不要用自动迁移(Test 4 的方式)。请坚持使用
cudaMallocHost
cudaMemcpy
长期(强烈推荐的修复):
请下载 GPU-Z (一个免费工具)。
打开它,查看 “Bus Interface” (总线接口) 字段。
点击旁边的问号
?
我几乎可以肯定它会显示
... @ x2 3.0
... @ x4 3.0
如果是这样,请关机,将您的 RTX 2060S 移动到主板最上面的那个 PCIe x16 插槽中。
gpuz检查:
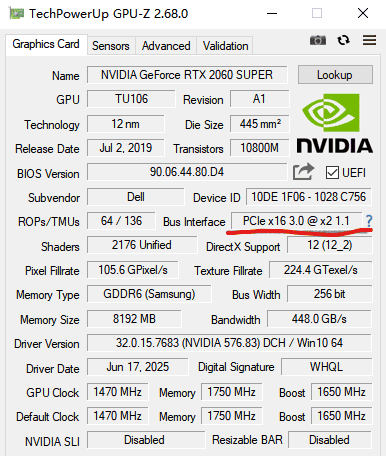
显示的是:
PCIe x16 3.0 @ x2 1.1
这是什么意思:
PCIe x16 3.0
@ x2 1.1
这个
x2
为什么这是个大问题?
显卡有 16 条“车道”可以用来和 CPU/内存通信,但它现在只在用 2 条车道。
PCIe 3.0 x16 (应有速度): 理论带宽约 15.75 GB/s
PCIe 3.0 x2 (您的速度): 理论带宽约 1.97 GB/s (或 ~1.83 GiB/s)
现在回头看测试结果:
[Test 1] Pinned (cudaMemcpy): 1.36 GiB/s
[Test 3] Pinned (cudaMemcpy): 1.52 GiB/s
实测速度(1.36 – 1.52 GiB/s)完美地符合一个
x2
结论:
cudaMemcpy
参考:https://mp.weixin.qq.com/s/Fkq-zl8mvUcs4pzGmZ6VJw
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...