
这里是码蜂AI智能体开源共享社区,点击上方【关注】,一起学习进步!
腾讯开源了一个知识库系统,名字是WeKnora。
值得关注的是,这款系统在核心设计思路上,与 IMA 知识库存在必定类似性,至少说明这类基于 RAG 的智能知识库正在变得越来越热门。
- 选 WeKnora:若需处理复杂文档、私有化部署或行业垂直场景(如法律、医疗),其开源性和深度解析能力更具优势。
- 选 IMA:若侧重个人 / 团队知识管理、云端、微信生态协同及轻量级创作,IMA 的易用性和云端服务更贴合需求。
WeKnora 是什么?
简单来说,WeKnora 是一个基于 RAG(检索增强生成)架构的智能知识库框架。专为企业级复杂文档场景设计的开源智能知识库框架。 它会先对文档进行语义检索,找到和问题最相关的上下文,再交由大语言模型生成答案。这样回答内容更准确、更可追溯,也避免了胡编乱造。
目前在 GitHub 上,WeKnora 的 star 已经超过 6.1k。
WeKnora项目地址:
https://github.com/Tencent/WeKnora
WeKnora 采用了模块化设计,构建了一条完整的“文档理解 + 检索 + 大模型推理”流水线。主要包括:
文档解析:支持上传常见的文本和 PDF。
向量化处理:把文档内容转化为向量,便于语义检索。
检索引擎:快速找到与提问最相关的片段。
大模型推理:调用本地或远程大模型生成答案。
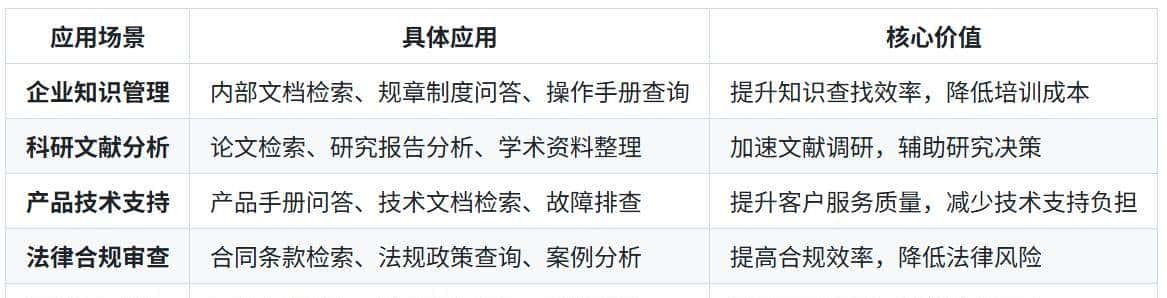
适用场景:
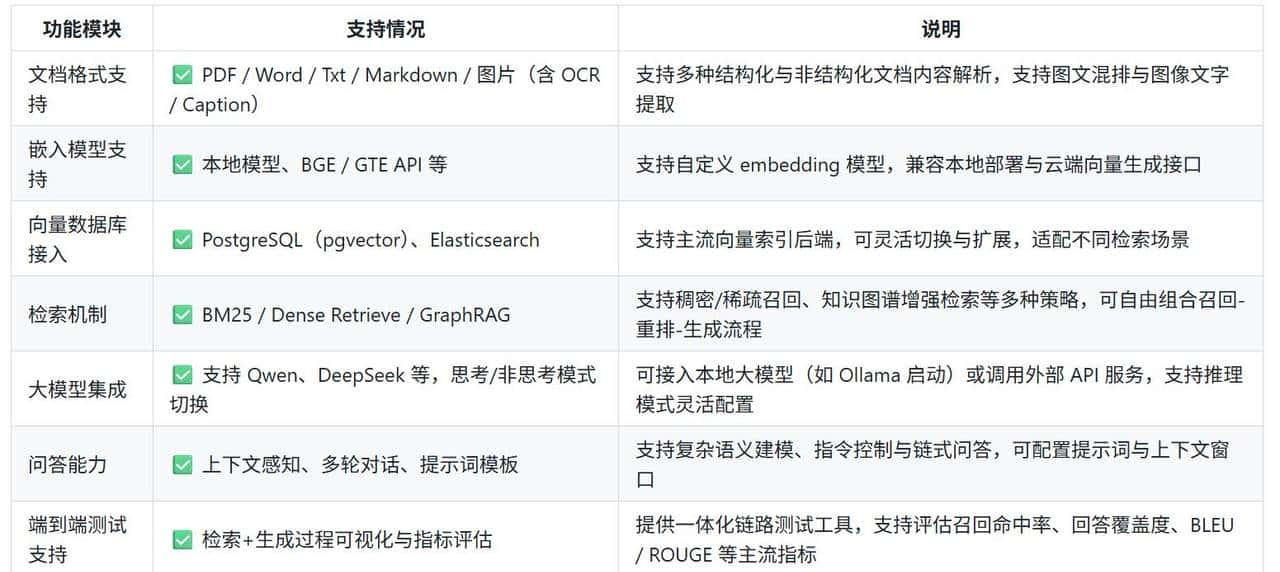
功能模块:
要是把企业里的文档堆比作 “乱成一锅粥的储物柜”—— 既有藏着表格公式的技术手册,又有混着图片的合同模板,还有存了三年的旧报告,那WeKnora就是个自带 “整理术 + 读心术” 的智能管家,专治各种 “找文档抓狂、问问题没谱” 的毛病。
FAQ常见问题
- 需要 GPU 吗? 答:推理阶段可选。用本地 Ollama + Qwen-7B,4 核 CPU 也能跑;追求速度可加一张 8 GB 显存的显卡。
- 数据会不会泄露? 答:完全离线部署时,数据只在内网硬盘。Docker 镜像可拉取后断网运行。
- 支持中文合同里的表格吗? 答:支持。表格会被解析成 Markdown 格式,再向量化检索,问答时能准确到“表 2-1 第三行”。
- 可以集成到公司现有系统吗? 答:提供 RESTful API,任何语言都可调用。返回 JSON 含答案、置信度、原文片段与页码。
- 如何更新知识库? 答:Web 界面支持“增量上传”。同名文件会覆盖旧版本,向量库自动更新。
- 是否支持权限管理? 答:开源版提供最基础的登录验证;企业版可对接 LDAP、OAuth2。
- 检索命中率低怎么办? 答:先在“链路追踪”里查看召回片段,如果相关度低,可调 BM25 权重或换 embedding 模型。
- 可以只搜索标题不搜索正文吗? 答:可以。检索策略支持“标题加权”,在配置文件里把 title_weight 调高即可。
- Docker 镜像多大? 答:完整镜像约 6 GB,含 Ollama+模型;如果自行托管模型,可缩减到 1.2 GB。
- 许可证允许商用吗? 答:MIT 许可证,可商用,只需保留原始版权声明。
本地部署教程和测试流程
1 本地部署
本地部署的环境要求:Docker、Docker Compose、Git
安装步骤如下:
1、克隆代码仓库
克隆主仓库
git clone https://github.com/Tencent/WeKnora.git
cd WeKnora
2、配置环境变量
复制示例配置文件
cp .env.example .env
编辑 .env,填入对应配置信息# 所有变量说明详见 .env.example 注释
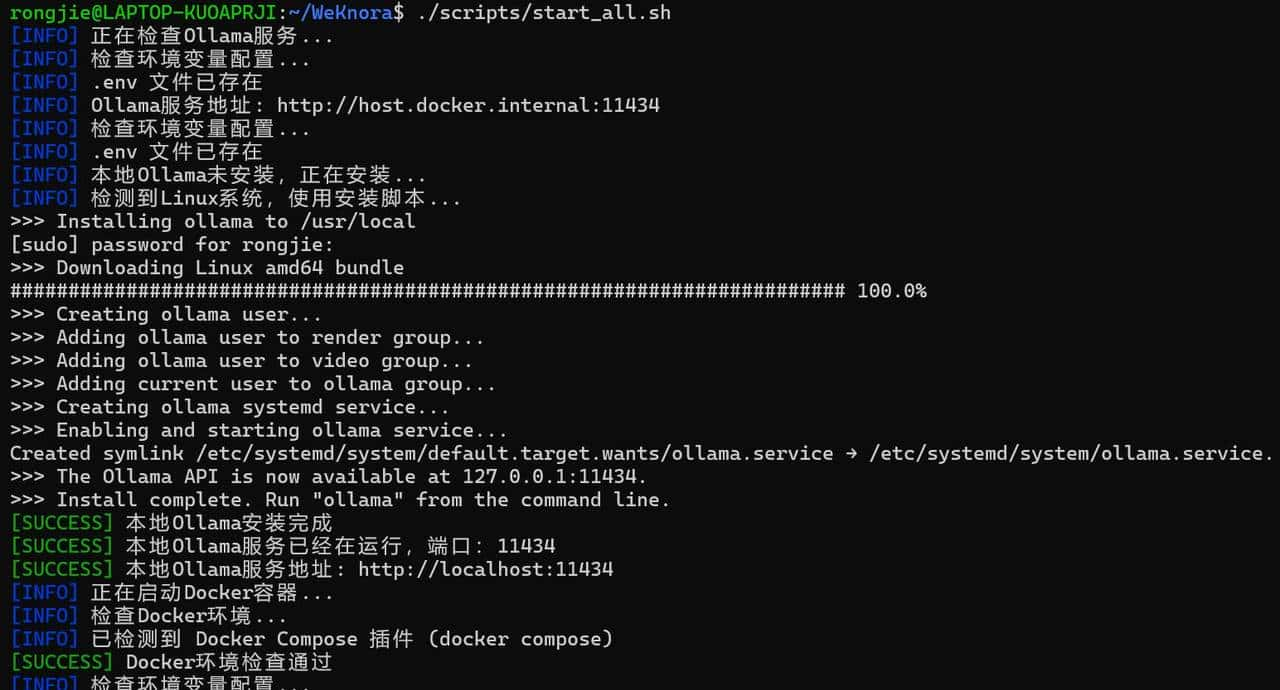
3、启动服务
启动全部服务(含 Ollama 与后端容器)
./scripts/start_all.sh
或
make start-all
4、停止服务
./scripts/start_all.sh –stop
或
make stop-all
启动成功是这样子的:
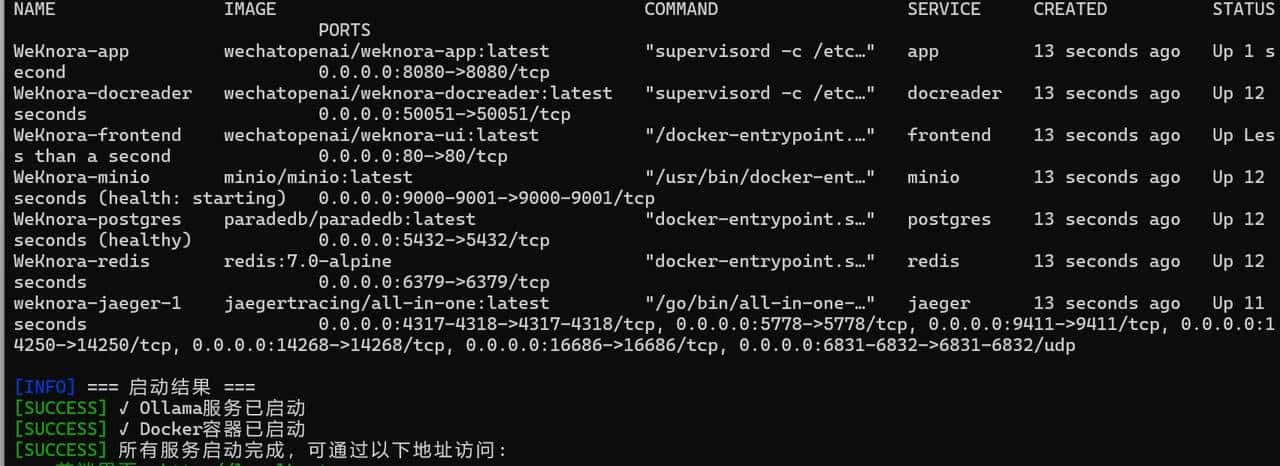
成功后,访问地址:http://localhost,可以看到初始化配置页面。
2 系统初始化配置
首次访问localhost会自动跳转到初始化配置页面,配置完成后会自动跳转到知识库页面。
请按照页面提示信息完成模型的配置。
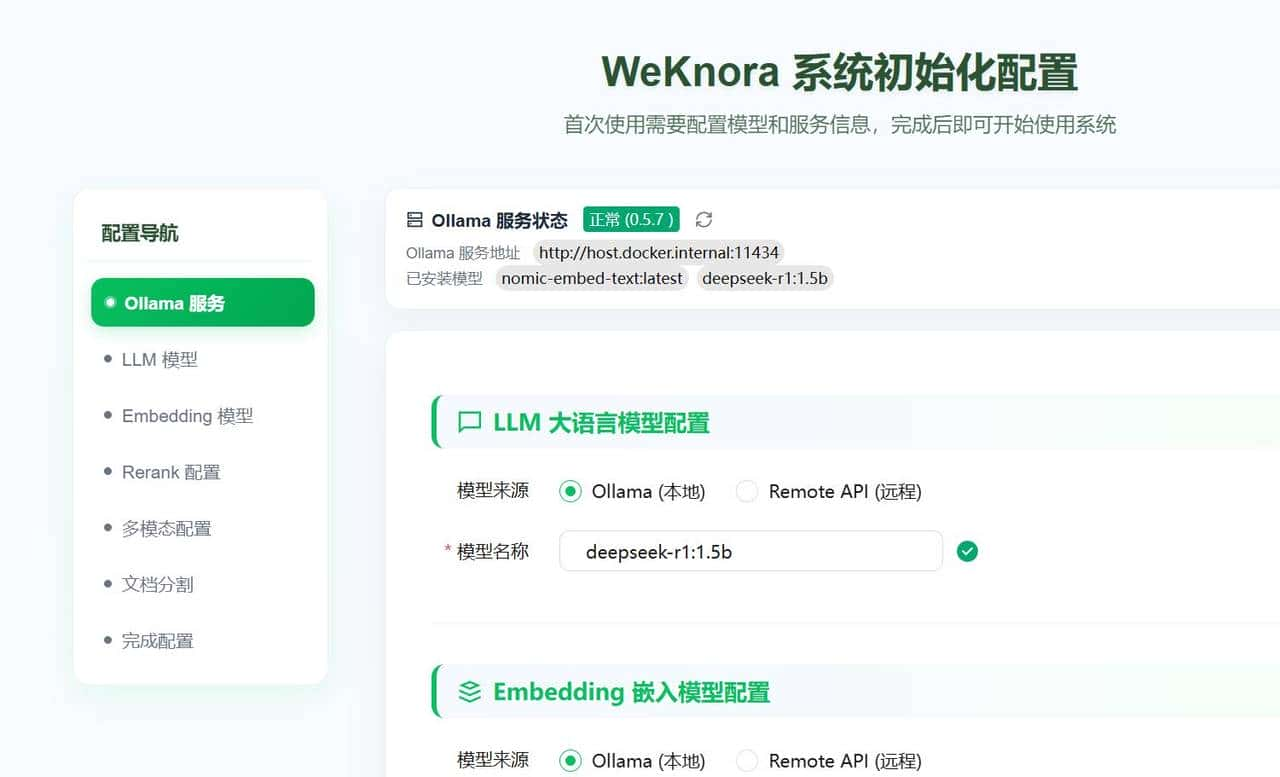
不过这里有个小重点:WeKnora 特 “接地气”,能认你电脑本地装的 Ollama 模型。咱先 “自查” 一下,看看自己电脑里到底有没有
再打开 http://localhost 这个地址,一眼就能瞅见 Ollama 的服务状态:亮着 “正常” 的绿灯,说明它在好好干活儿。
已经检测到了我本地安装的deepseek-r1:1.5b和nomic-embed-text:latest模型。
如果你使用本地模型,就把这两个模型添加到LLM大语言模型和Embedding嵌入模型配置中。
当然了,如果我们想要远程的模型也是可以的。
这里我就都改成硅基流动上面的DeepSeek最新的V3.1模型。
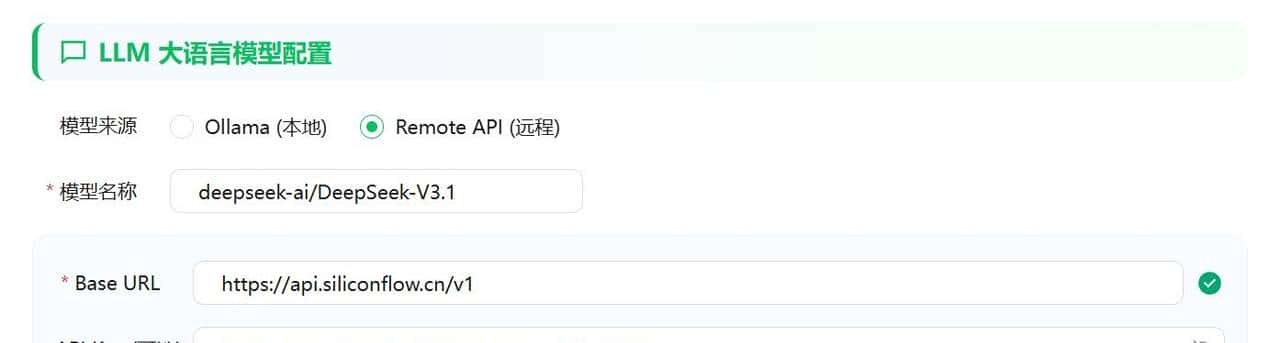
硅基流动API的URL地址:
https://api.siliconflow.cn/v1
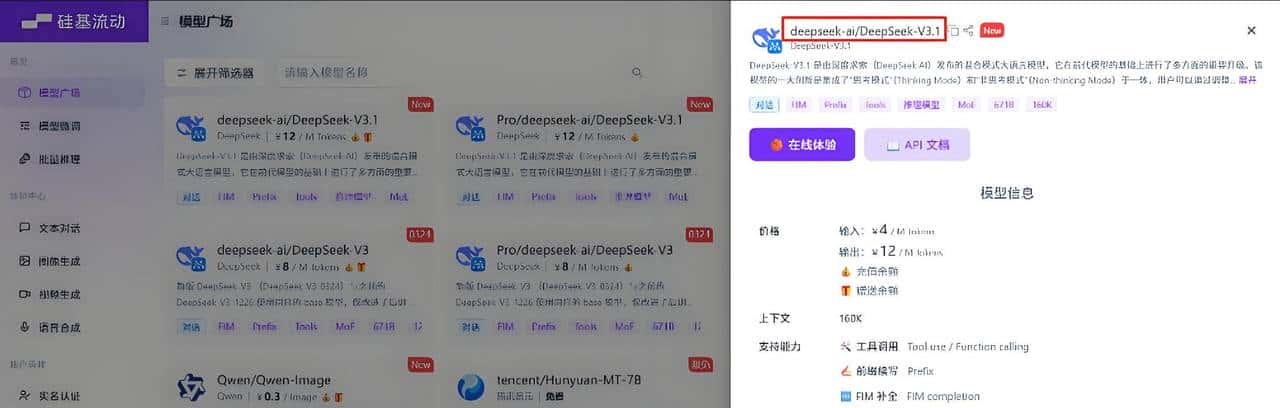
这个模型名称必须是要和硅基流动广场中的模型名称一模一样。
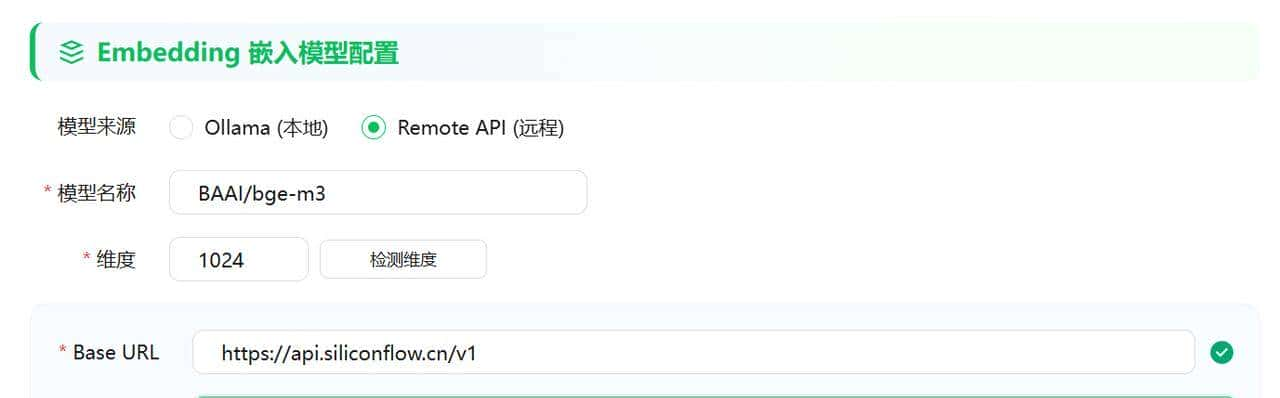
向量模型也改成硅基流动的BAAI/bge-m3模型。
Rerank重新排序模型选择了BAAI/bge-reranker-v2-m3,都可以根据自己实际情况进行更改。
多模态选择了千问的
Qwen/Qwen2.5-VL-72B-Instruct。
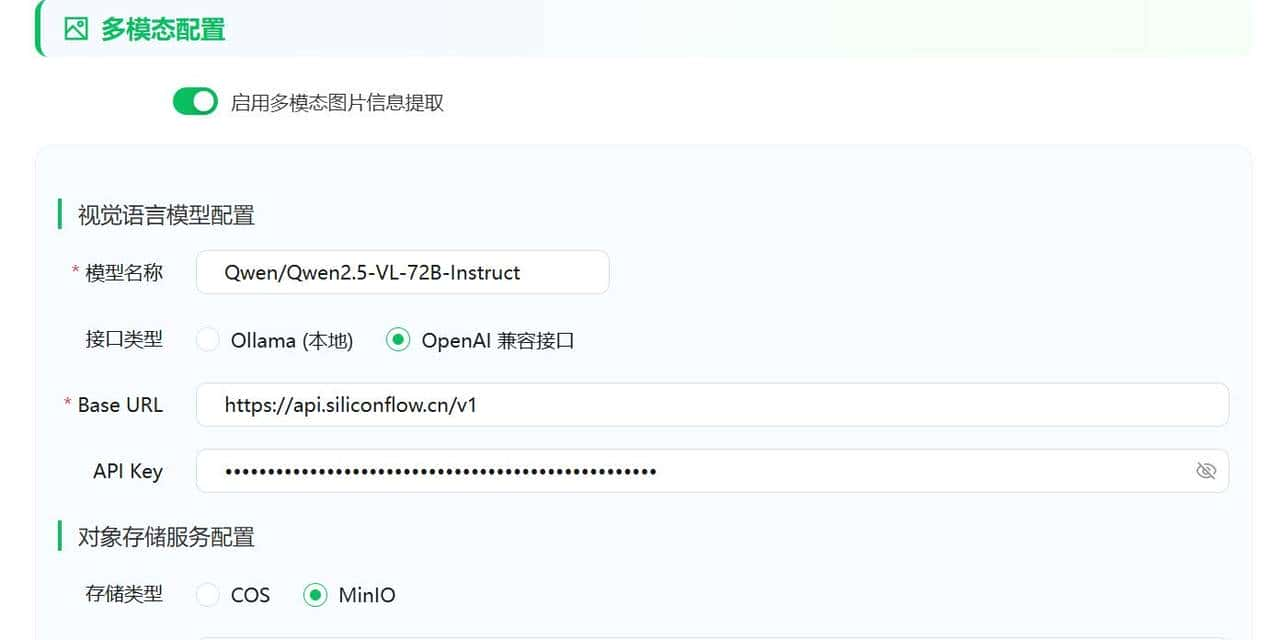
需要上传一张本地的图片进行测试,可以看到图片被正常识别出来了。
只上传单张图片:
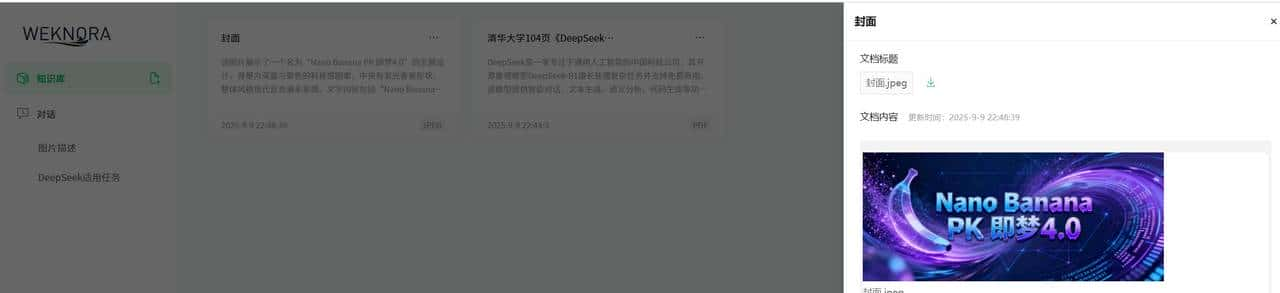
最后就是文档分割配置,分割策略可以选择均衡模式、精准模式、上下文模式、自定义。
只有在自定义模型下,才可以手动设置参数,分块大小、分块重叠及分隔符设置。
这样我们就完成了配置,后续也可以在设置中进行更改。
3 使用知识库
配置完成后就可以使用知识库了。
3.1 测试PDF文档
先上传一个PDF文件,清华大学那个DeepSeek使用的文档。
点击文档可以看到右侧显示分段的详情信息。

然后就是我们熟悉的向知识库提问环节。
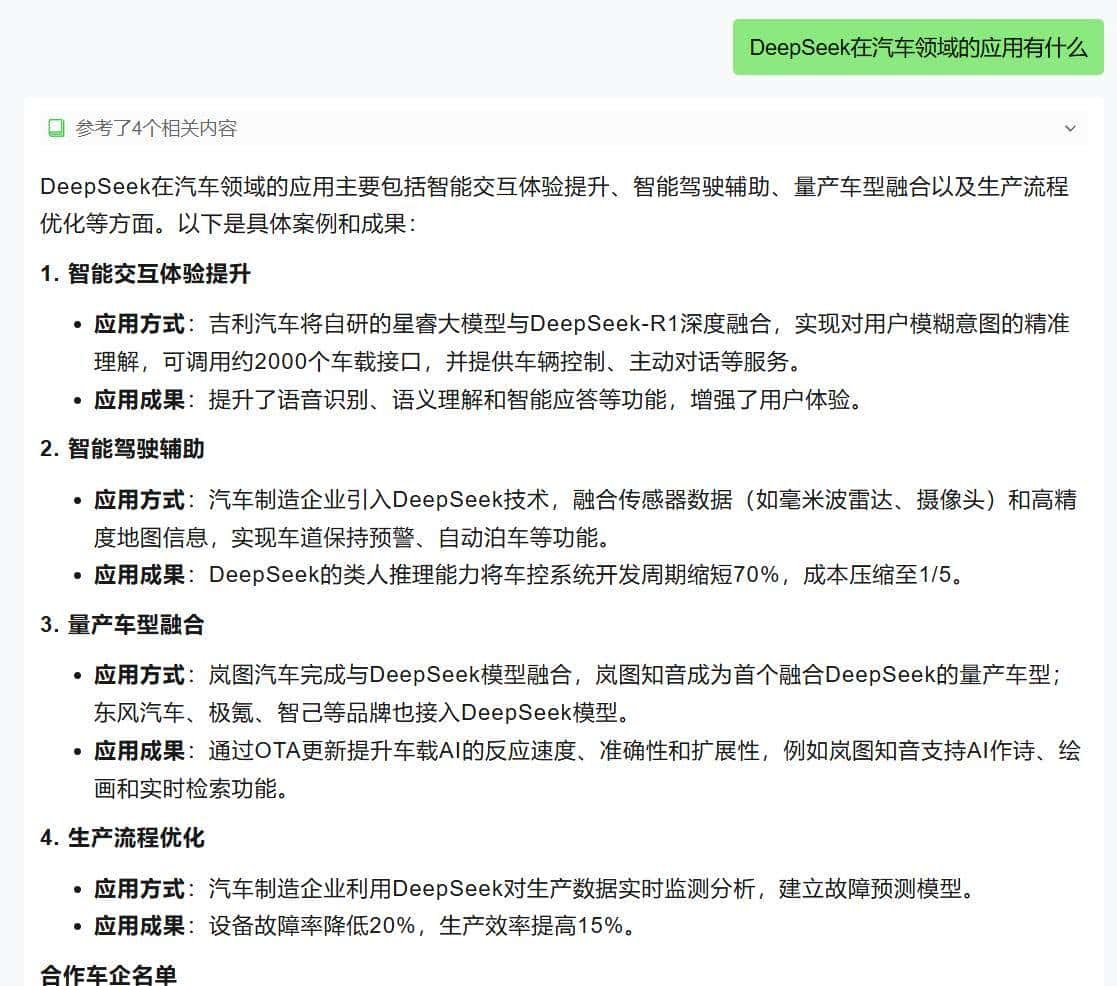
这个问题DeepSeek适合做什么任务是结合了PDF中好几页的内容。
系统能从文档的多个部分整合答案,并在结果中显示引用来源。
在测试一个,我又上传了《浙江大学:DeepSeek行业应用案例集》的PDF文件测试:
问个无关的问题,目前正火的预置菜问题,可以看到如果知识库没有此内容,回复是无法回答。

WeKnora 目前还有一些限制,列如:
暂时只支持单文件上传;
不能同时管理多个知识库;
总结下:WeKnora 就是帮用户解决 “文档乱、找得慢、用得慌” 的痛点 —— 不用再对着一堆文件抓狂,不用再怕问问题没依据,不用担心里敏感数据泄密,像个靠谱的 “文档小助手”,把复杂的知识捋顺了,让你用着省心又省事。
© 版权声明
文章版权归作者所有,未经允许请勿转载。














似乎有点东西
收藏了,感谢分享
部署不成功的有木有