
在 GPT-4o、Gemini-2.5 Pro 等通用大模型刷新 OCR 榜单的同时,产业界仍面临一个“老问题”:如何把扫描版 PDF、手机拍照、旧档案等“高分辨率、高密度、高噪声”的文档图像,快速、精准、低成本地还原成结构化数据?
一、OCR产业界的瓶颈和已有的方案
- 高分辨率文档解析的矛盾
(1) 分辨率-效率矛盾:A4 扫描件 300 dpi 即 3500×4900 像素,ViT 类模型若原图编码,视觉 token 数≈hw/14²≈3.0×10⁵,计算量 O(N²) 不可承受。
(2) 密度-语义矛盾:文档区域 80% 为空白或低信息像素,端到端模型产生大量冗余 token,导致“高显存占用+低信噪比”,易触发幻觉。
(3) 颗粒度-一致性矛盾:传统管线把版面分析、阅读顺序、公式识别、表格结构等任务拆成独立模型,虽然单模块可解释,但误差级联、风格不一致,难以联合优化。 - 已有方案的局限性
- 传统管线(MinerU-pipeline、PP-StructureV3)
• 模块化:检测→分类→识别→排序,单点优化容易。
• 局限:旋转/跨栏/空白页鲁棒差;超参数爆炸;维护成本高。 - 通用 VLM(GPT-4o、Gemini-2.5 Pro)
• 优点:语义先验强,零样本泛化好。
• 局限:高分辨率需切 patch,推理贵;长文档幻觉;商用 API 费用高。 - 端到端文档 VLM(dots.ocr、MonkeyOCR、olmOCR)
• 优点:统一架构,端到端梯度回传。
• 局限:全图原生分辨率训练,显存占用大;表格 HTML 序列冗长,大表易崩溃;长公式结构幻觉严重。
本次分享的MinerU2.5,重点要解决一下三个问题:
- 如何在“保持原生分辨率细节”的同时“把计算复杂度降一个数量级”?
- 如何在不依赖多模型级联的前提下,实现“版面+阅读顺序+内容”一致输出?
- 如何针对“超长公式、旋转表格、少线表、水印干扰”等硬场景,提出可复现、可扩展的数据与训练策略?
针对这些痛点MinerU2.5提出了1.2 B 轻量级文档解析模型,
二、MinerU2.5
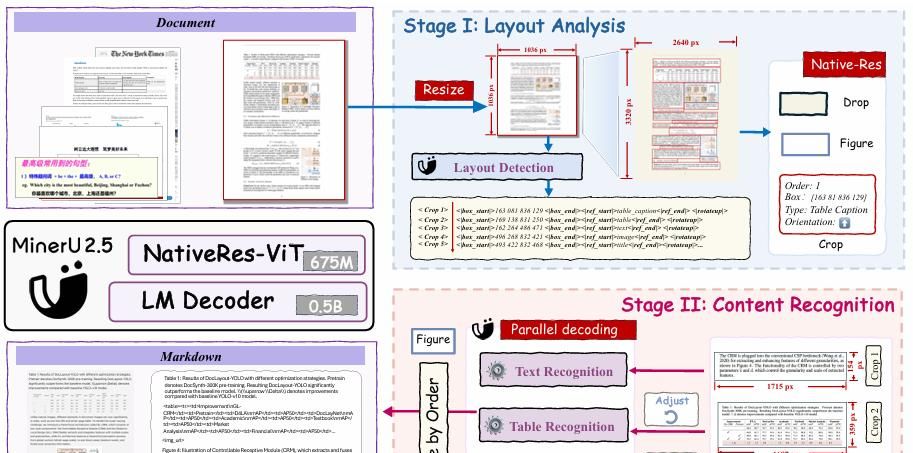
MinerU2.5 的核心思想是“先全局后局部、先结构后语义”的解耦范式。 Stage-I Layout Analysis:低分辨率缩略图→快速全局版面检测+阅读顺序+旋转角;
Stage-II Content Recognition:依布局裁剪原图关键区→并行送入原生分辨率 ViT→轻量 0.5 B LM 解码,输出 OCR/公式 LaTeX/表格 OTSL。
虽然整体参数量仅 1.2 B,但通过“分辨率-任务双解耦”把推理 FLOPs 降到端到端方案的 1/10,同时保持原生像素级精度。
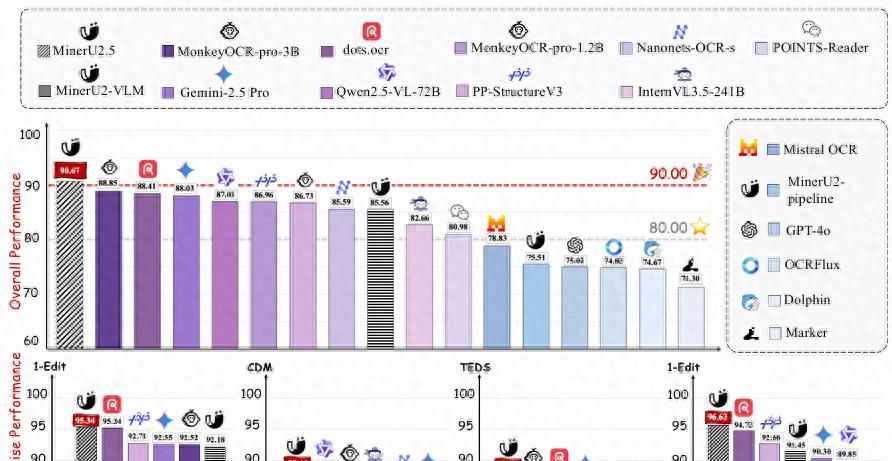
通过“解耦布局-内容两阶段”、“原分辨率裁剪窗口”、“OTSL 表结构语言”、“原子公式分解重组”等创新,在 OmniDocBench、olmOCR-bench 等 5 大公开基准上取得 90.67 综合分,超越 3.7 B 的 MonkeyOCR-pro-3B 与 72 B 的 Qwen2.5-VL;单卡 RTX 4090 吞吐达到 2.12 页/s,比现有方案快 4–7 倍。
- 宏观架构
ViT Encoder (675 M) + PatchMerger (2×2 pixel-unshuffle) + Qwen2-Decoder (0.5 B)
• 输入:动态分辨率,最大 2048×28×28 token;
• 位置编码:2D-RoPE 保持相对坐标;
• 输出:自回归解码,支持三种 prompt 模板(Layout/OCR/Formula/Table)。 - PatchMerger 的取舍
Adjacent 2×2 token 合并,通道×4、空间/4,FLOPs/4;实验表明在 300 dpi 文档解析任务上 BLEU 仅降 0.4%,但吞吐提升 2.3×。 - 异步两阶段部署
基于 vLLM 扩展:
• Stage-I 与 Stage-II 解耦为独立 cuda stream,CPU 预处理与 GPU 推理重叠;
• 动态 batch:缩略图固定 batch=16,裁剪图根据空域填充策略动态组 batch;
• 采样惩罚:对 table/formula 降低 frequency_penalty,防止“”等合法重复被抑制。
2.1 解决高分辨率输入计算爆炸
- 两阶段解析 + 原生分辨率窗口裁剪
- 缩略图分支:统一 resize 到 1036×1036,NaViT-675 M 编码,视觉 token 仅 4k,负责检测版面元素类别、位置、旋转角、阅读顺序。
- 原图分支:按 Stage-I 给出的 4 维框 (x,y,w,h,θ) 反向投影到 300/400 dpi 原图,裁剪后最长边≤2048 像素,再送入同一 ViT,token 数 4–2048 可调。
- 两分支共享权重,训练时随机丢弃缩略图或原图,实现“单模型-双推理模式”。
例如:输入一页双栏论文 3400×4400。Stage-I 缩略图→0.07 s 检出 46 个区域(标题、公式、表、页眉、页脚、图注)。系统把“公式 3”区域裁剪得 1124×224 原图,送入 ViT→LM,4.3 ms 完成 LaTeX 解码,而整页端到端方法需 2.1 s。
2.2 解决版面元素标签混乱、阅读顺序难
- 统一层级标签体系 + 多任务并行
- 提出 25 类细粒度标签:text/title/phonetic/figure/chart/algorithm/code-caption/footnote/page-number…,覆盖非正文元素。
- 把版面分析重定义为“四合一”任务:框位置+类别+旋转角+阅读顺序序号,一次性向量输出,避免后处理规则。
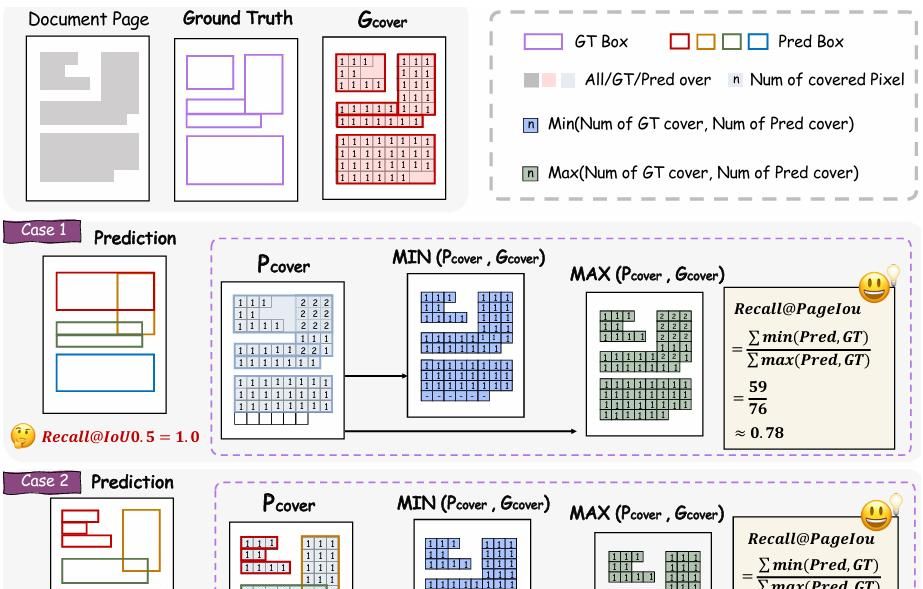
- 新指标 PageIoU:把预测/真值转 0-1 覆盖图,像素级 IoU,解决传统 mAP 对“换行/段”颗粒度敏感问题。
例如:对旋转 90° 的宽表,Stage-I 直接输出“table, θ=90°, order=15”,后续裁剪时先旋转再识别,避免以往“检测-旋转-再检测”级联误差。
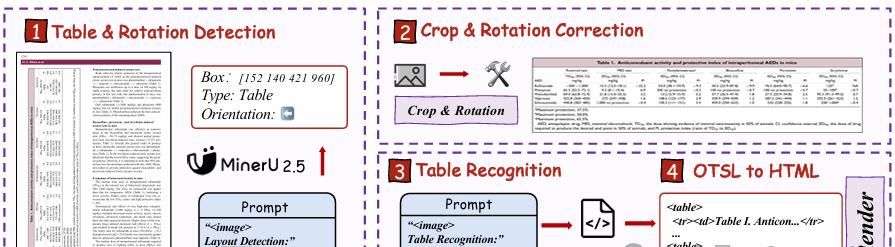
2.3 解决表格 HTML 序列冗长、大表易断
- OTSL 中间语言 + 四阶段管线
- 检测表格+旋转角;
- 几何校正→ crop;
- VLM 解码为 OTSL(IBM 2023 提出,仅 5 个 token 表达单元格边界,平均长度比 HTML 短 50%);
- 规则转 HTML/Excel/LaTeX
举个例子:<nl><fcel>Head1<fcel>Head2<lcel>RowSpanCell<nl><lcel>, 模型只需学习“视觉-结构”对齐,无需记忆 HTML 标签嵌套。
对 80 行×10 列金融报表,MinerU2.5 输出 421 token OTSL,而 dots.ocr 需 2380 token HTML,推理延迟 1/3,TEDS-S 提升 4.3 分。
2.4 解决长公式结构幻觉、多行对齐错误
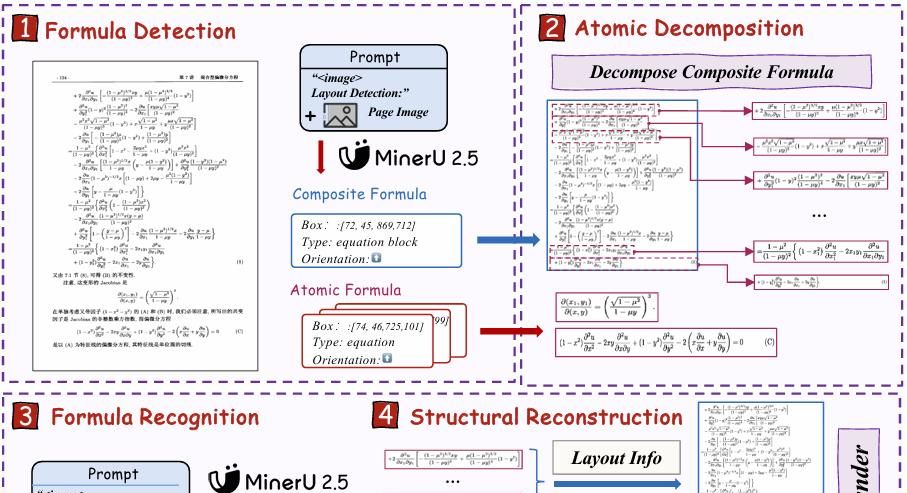
- Atomic Decomposition & Recombination (ADR)
- 把公式分为 atomic(单矩阵、单分式)与 compound(多行推导)。
- Stage-I 先给出每行 atomic box 及纵向对齐关系(如 alignat、eqnarray)。
- 逐行识别→得 LaTeX 片段→按对齐模板重组。
- 引入 CDM (Character Detection Matching) 指标:渲染后比对像素,避免 LaTeX 语法等价但字符串不同被误判。
举个例子:对 8 行推导,ADR 将其切成 8 张 1024×96 图,每图 1.8 ms 得 LaTeX,最终拼接为
egin{align} … end{align},CDM 得分 88.46,高于 MonkeyOCR-3B 的 87.45。
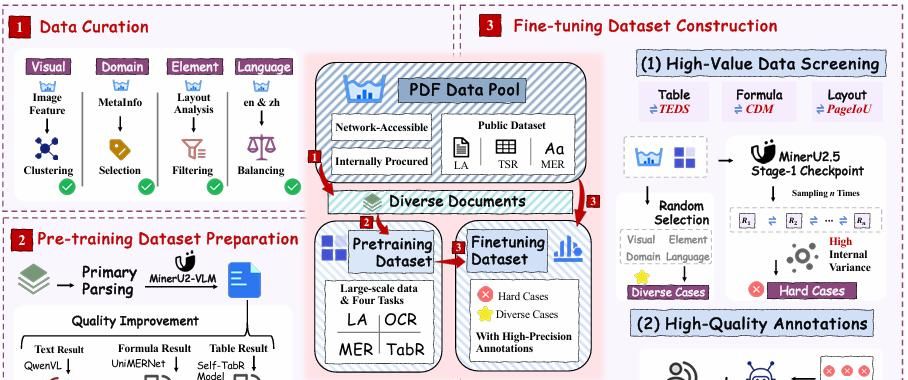
2.5 解决训练数据噪声大、难例缺失

- 闭环 Data Engine + IMIC 自举
- 大规模粗标:用 MinerU-pipeline 跑 4200 万页 PDF,得 6.9 M 样本。
- 专家模型精标:文本用 Qwen2.5-VL-72B 校正,公式用自研 UniMERNet,表格用自研 Self-TabR。
- IMIC(Inference-consistency Mining):对未标注数据做 5 次随机解码,PageIoU<0.8 或 TEDS<0.6 的样本视为“难例”,送人工复核→得到 630 K 高质量 SFT。
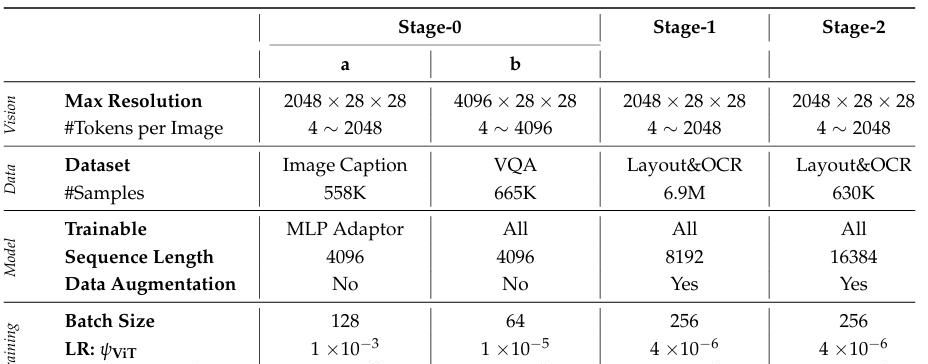
- 训练三阶段:
Stage-0 图文对齐:只训 MLP,冻住 ViT+LM;
Stage-1 文档预训练:全参数,6.9 M 混合样本,2 epoch;
Stage-2 难例微调:630 K 难例 + 随机 20% 普通例,3 epoch,学习率 4e-6。
三、可借鉴的创新点与启示
- “分辨率-任务”双解耦思想
不仅限于文档,任何“大图像+局部高密度”任务(医学影像、遥感、工业质检)均可套用:先缩略图定位 ROI→原图裁剪精细分析,兼顾效率与精度。 - 轻量级统一模型
1.2 B 参数即可在 5 项任务刷榜,证明“数据工程+难例自举”比盲目堆参数更有效;对边缘部署友善,RTX 4090 单卡可跑 30+ QPS。 - 中间语言设计
OTSL、ADR 启示我们:与其让模型硬背 HTML/LaTeX 语法,不如先学习“视觉-结构”极简表达,再规则转标准格式,降低自回归长度与幻觉。 - 一致性自举难例挖掘
IMIC 不依赖人工规则,用“模型自身不确定性”自动发现边界样本,通用且可迭代;可无缝迁移到信息抽取、VQA、图表理解等任务。
https://github.com/opendatalab/MinerU
https://huggingface.co/opendatalab/MinerU2.5-2509-1.2B
https://arxiv.org/pdf/2509.22186
© 版权声明
文章版权归作者所有,未经允许请勿转载。










![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/2.jpg)



中文也行?
我在3060的显卡上跑的,能接受,比在线大模型还快点
没人试用吗
收藏了,感谢分享
用过了,效果相当可以,复杂表格识别精度跟在线大模型差不多,而且有些感觉更好