
虽然RAG很火,但真到了具体业务里,坑还是一个接一个。最近在推进RAG应用落地的过程中,业务方就遇到了一个看似“智商堪忧”的问题。
业务场景简介:合同审查 + 审核条款
这是一个标准的“结构化规则 + 非结构化合同”的RAG应用:
- 业务方在知识库中录入了大量合同审核条款,例如:
- “合同类型是买卖合同,审核立场是买方,审核条款为……”
- “合同类型是买卖合同,审核立场是卖方,审核条款为……”
这些条款是根据合同类型 + 审核立场组合出的规则性内容,结构清晰、表达标准,本以为用语义检索会稳稳地命中对应条款。
结果,测试一跑——大家傻眼了。
问题来了:买方也匹配卖方?!
当业务方在知识库中查询:
“合同类型是买卖合同,审核立场是买方”
理论上,知识库应该返回所有“买方立场”的审核条款才对。
但实际情况是:
- “买方立场”的条款当然被召回了;
- “卖方立场”的条款也被召回了;
- 而且得分还很高,几乎难以区分!
连加上Reranker之后也没有太大改观,业务方崩溃:“知识库傻得可爱,连买方和卖方都搞不清!”

深层缘由解析:语义模型的局限性
这个问题,实则是当前主流语义向量模型天然的“知识盲区”:
语义嵌入的近义性问题
像 bge 这样的语义模型,对于“买方”和“卖方”这种概念,不会像人类那样理解它们的对立关系,而是认为它们都属于“合同角色”范畴,语义相关性很强,导致它们在向量空间中距离超级近。所以模型认为这两条是“很像的内容”。
Rerank依然是“类似度”导向
即便我们加上Rerank模型(如 bge-reranker-v2-m3),它的排序逻辑仍是“基于语义”的,而不是“基于逻辑规则”。对于“买方”和“卖方”这样的细粒度词汇对立关系,模型是分不清楚的。于是,RAG检索逻辑就成了“语义近=相关”,完全忽略了业务中最关键的“角色精度”!
有什么解法?
坑一:不要用纯语义向量去匹配结构化规则
像这种强结构、强筛选条件的内容,本质上就是“结构化数据”,不适合用“语义匹配”来检索。
最推荐的方式是:
✨直接存进数据库,配条件过滤,查什么得什么!
但现实是……
业务方拒绝:我就想用知识库!
业务方说得很清楚:
“Dify 已经有知识库维护后台了,咱不能再搞一套表单后台让大家维护两份数据。工作流也全在 Dify 里,非得集成数据库太麻烦了。”
所以,我们只能再在 Dify 的知识库能力上动脑筋。
破局关键:利用 Dify 的“元数据过滤能力”!
好消息是,从 Dify 1.1.3 开始,知识库支持了元数据过滤!
实施方案:
将每类合同、审查立场的条款拆分成一个个独立文档
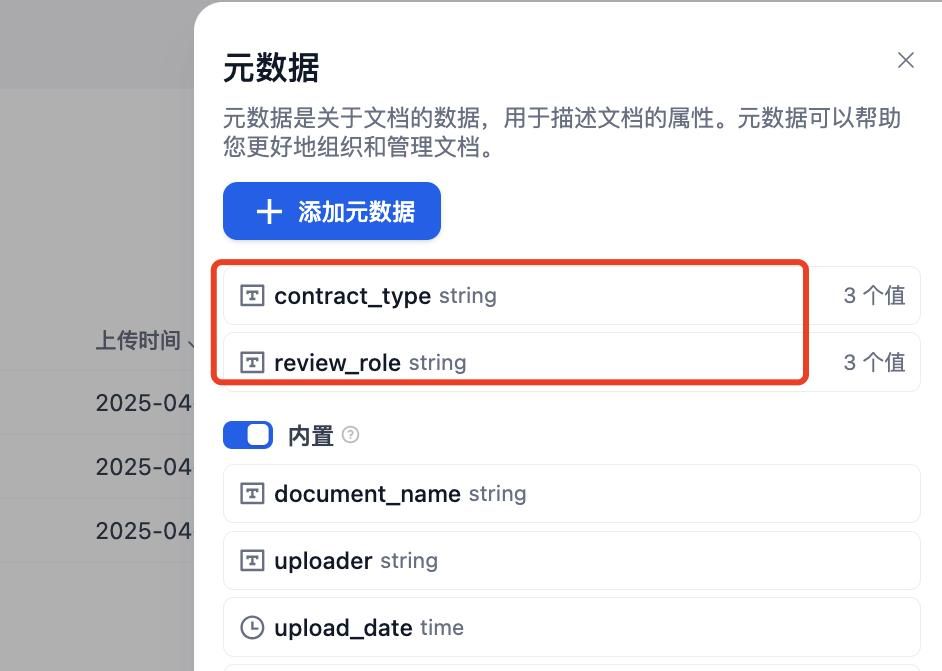
为每个文档配置元数据
- contract_type: 买卖合同
- review_role: 买方 或 卖方

在工作流中使用知识检索节点时开启元数据过滤
- 动态地把用户输入中的“合同类型”和“审核立场”提取出来
- 将其作为检索过滤条件,确保只召回对应条款
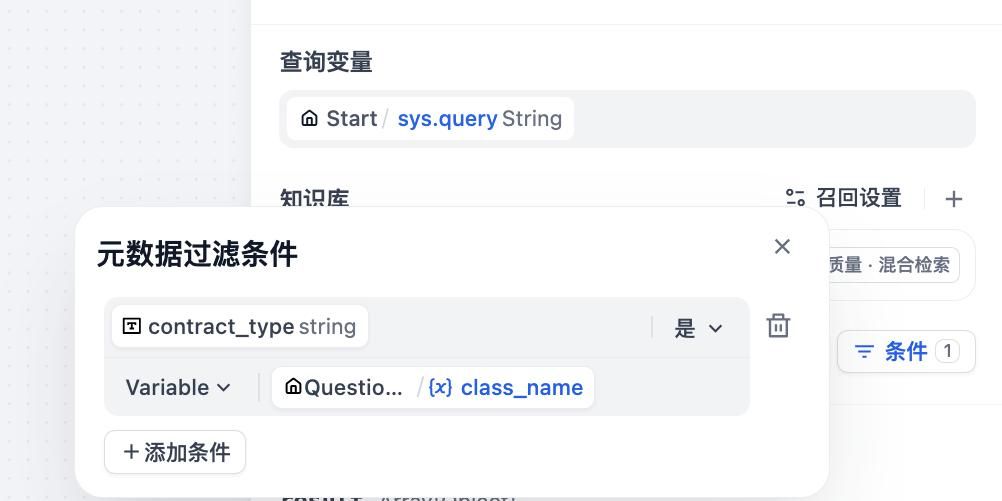
这样一来,模型不需要“理解”买方和卖方的区别,我们直接用结构信息排除干扰,真正实现语义 + 规则的协同工作!
总结
Dify 的元数据过滤机制,为结构化规则在非结构化知识库中的“嵌入式表达”提供了路径,是业务可接受、工程可实现的中间解法。
业务落地,就是一个不断折中和打磨的过程。别怕知识库“傻得可爱”,我们可以让它“机智工作”!
如果你觉得这篇文章对你有协助,别忘了点赞 收藏✨ 转发给你的技术小伙伴哈!
© 版权声明
文章版权归作者所有,未经允许请勿转载。











![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/2.jpg)



收藏了,感谢分享
规则那么多吗?直接写出来不好吗?非得放知识库?
感谢经验分享
感谢友友的分享👏👏👏👏
受教了多谢分享。
是较慢,200 个文档,要二十分钟左右,当然看文档大小
可能需要抽成graph
挺好的思维方式。后续如果有条款同时要查买方卖方,比如违约条款要同时分析追溯两者关联信息,可能又不行了,得上其它手段。
我在本地调试使用了一下,感觉上传文件太慢了,不知有没有好办法解决。
你是用的云服务版本吗