JSON概述
在Python中,我们可以将程序中的数据以JSON格式进行保存。JSON是“JavaScript Object Notation”的缩写,它本来是JavaScript语言中创建对象的一种字面量语法,目前已经被广泛的应用于跨语言跨平台的数据交换。使用JSON的缘由超级简单,由于它结构紧凑而且是纯文本,任何操作系统和编程语言都能处理纯文本,这就是实现跨语言跨平台数据交换的前提条件。目前JSON基本上已经取代了XML(可扩展标记语言)作为异构系统间交换数据的实际标准。可以在JSON的官方网站找到更多关于JSON的知识,这个网站还提供了每种语言处理JSON数据格式可以使用的工具或三方库。
{
"name": "张三",
"age": 30,
"is_student": False,
"courses": ["数学", "英语", "计算机"],
"address": {
"street": "人民路123号",
"city": "北京"
}
}在JSON中使用的数据类型(JavaScript数据类型)和Python中的数据类型也是很容易找到对应关系的,大家可以看看下面的两张表。
表1:JavaScript数据类型(值)对应的Python数据类型(值)
|
JSON |
Python |
|
object |
dict |
|
array |
list |
|
string |
str |
|
number |
int / float |
|
number(real) |
float |
|
boolean(true/ false) |
bool (True/ False) |
|
null |
None |
表2:Python数据类型(值)对应的JavaScript数据类型(值)
|
Python |
JSON |
|
dict |
object |
|
list/ tuple |
array |
|
str |
string |
|
int/ float |
number |
|
bool(True/ False) |
boolean(true / false) |
|
None |
null |
python 中json模块有四个比较重大的函数,分别是:
- dump – 将Python对象按照JSON格式序列化到文件中
- dumps – 将Python对象处理成JSON格式的字符串
- load – 将文件中的JSON数据反序列化成对象
- loads – 将字符串的内容反序列化成Python对象
1. 基本JSON操作
import json
# Python字典数据
data = {
"name": "张三",
"age": 30,
"is_student": False,
"courses": ["数学", "英语", "计算机"],
"address": {
"street": "人民路123号",
"city": "北京"
}
}
# 将Python对象转换为JSON字符串
json_string = json.dumps(data, indent=4, ensure_ascii=False)
print("JSON字符串:")
print(json_string)
# 将JSON字符串保存到文件
with open('data.json', 'w', encoding='utf-8') as f:
json.dump(data, f, indent=4, ensure_ascii=False)
# 从文件读取JSON数据
with open('data.json', 'r', encoding='utf-8') as f:
loaded_data = json.load(f)
print("
从文件加载的数据:")
print(loaded_data)2、复杂数据类型处理
import json
from datetime import datetime
# 包含复杂数据类型的Python对象
complex_data = {
"timestamp": datetime.now(),
"set_data": {1, 2, 3},
"custom_object": type('CustomClass', (), {'attr': 'value'})
}
# 自定义JSON编码器处理复杂类型
class ComplexEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime):
return obj.isoformat()
elif isinstance(obj, set):
return list(obj)
elif hasattr(obj, '__dict__'):
return obj.__dict__
return super().default(obj)
# 序列化复杂对象
json_string = json.dumps(complex_data, cls=ComplexEncoder, indent=2)
print("复杂对象JSON:")
print(json_string)3. JSON配置文件管理
import json
import os
# 配置文件路径
CONFIG_FILE = 'config.json'
# 默认配置
default_config = {
"app_name": "MyApp",
"version": "1.0",
"settings": {
"theme": "dark",
"language": "zh-CN",
"auto_update": True
}
}
# 检查并创建配置文件
if not os.path.exists(CONFIG_FILE):
with open(CONFIG_FILE, 'w', encoding='utf-8') as f:
json.dump(default_config, f, indent=4)
print("已创建默认配置文件")
# 读取配置文件
with open(CONFIG_FILE, 'r', encoding='utf-8') as f:
config = json.load(f)
print("当前配置:")
print(json.dumps(config, indent=4, ensure_ascii=False))
# 修改并保存配置
config['settings']['theme'] = 'light'
config['version'] = '1.1'
with open(CONFIG_FILE, 'w', encoding='utf-8') as f:
json.dump(config, f, indent=4)
print("
配置已更新")4. 处理JSON API响应
import json
import urllib.request
from pprint import pprint
# 从API获取JSON数据
def fetch_json_data(url):
with urllib.request.urlopen(url) as response:
data = json.loads(response.read().decode('utf-8'))
return data
# 示例API (JSONPlaceholder)
api_url = "https://jsonplaceholder.typicode.com/users/1"
try:
user_data = fetch_json_data(api_url)
print("从API获取的用户数据:")
pprint(user_data)
# 保存到本地
with open('user_data.json', 'w', encoding='utf-8') as f:
json.dump(user_data, f, indent=2, ensure_ascii=False)
print("
数据已保存到 user_data.json")
except Exception as e:
print(f"获取数据时出错: {e}")5. JSON数据验证
import json
from jsonschema import validate, ValidationError
# JSON数据
user_data = {
"id": 1,
"name": "John Doe",
"email": "john@example.com",
"age": 30
}
# JSON Schema定义
schema = {
"type": "object",
"properties": {
"id": {"type": "number"},
"name": {"type": "string"},
"email": {"type": "string", "format": "email"},
"age": {"type": "number", "minimum": 18}
},
"required": ["id", "name", "email"]
}
# 验证JSON数据
try:
validate(instance=user_data, schema=schema)
print("JSON数据验证通过")
except ValidationError as e:
print(f"验证错误: {e}")包管理工具pip
Python标准库中的json模块在数据序列化和反序列化时性能并不是超级理想,为了解决这个问题,可以使用三方库ujson来替换json。所谓三方库,是指非公司内部开发和使用的,也不是来自于官方标准库的Python模块,这些模块一般由其他公司、组织或个人开发,所以被称为三方库。虽然Python语言的标准库虽然已经提供了诸多模块来方便我们的开发,但是对于一个强劲的语言来说,它的生态圈必定也是超级繁荣的。
之前安装Python解释器时,默认情况下已经勾选了安装pip,大家可以在命令提示符或终端中通过pip –version来确定是否已经拥有了pip。pip是Python的包管理工具,通过pip可以查找、安装、卸载、更新Python的三方库或工具,macOS和Linux系统应该使用pip3。例如要安装替代json模块的ujson,可以使用下面的命令。
pip install ujson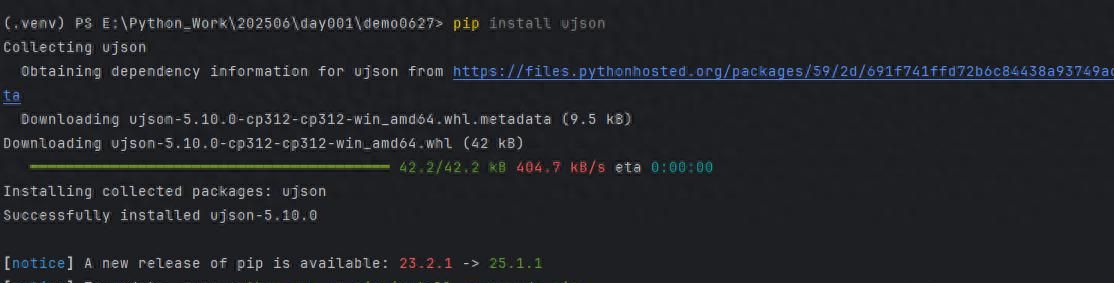
在默认情况下,pip会访问https://pypi.org/simple/来获得三方库相关的数据,但是国内访问这个网站的速度并不是十分理想,因此国内用户可以使用豆瓣网提供的镜像来替代这个默认的下载源,操作如下所示。
可以通过pip search命令根据名字查找需要的三方库,可以通过pip list命令来查看已经安装过的三方库。如果想更新某个三方库,可以使用pip install -U或pip install –upgrade;如果要删除某个三方库,可以使用pip uninstall命令。
1、搜索ujson三方库
pip search ujson
pip index versions ujson (Python 3.10+查看可用的版本)2、查看已经安装的三方库
pip list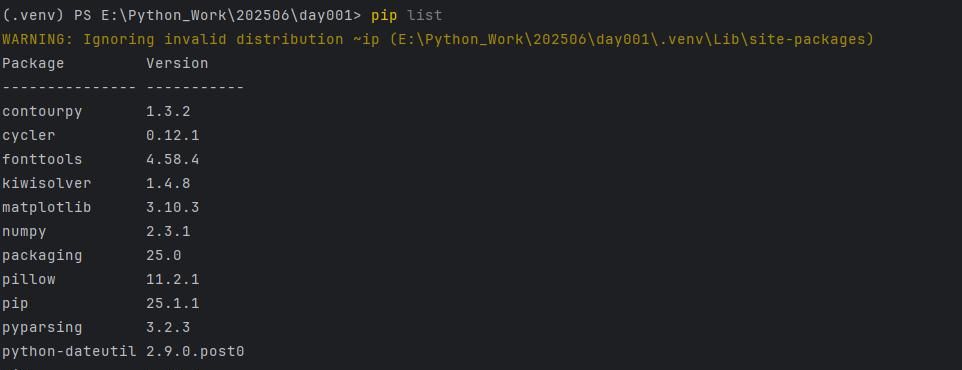
3、更新ujson三方库
pip install -U ujson4、删除ujson三方库
pip uninstall -y ujson提示:如果要更新pip自身,对于macOS系统来说,可以使用命令pip install -U pip。在Windows系统上,可以将命令替换为python -m pip install -U –user pip。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...