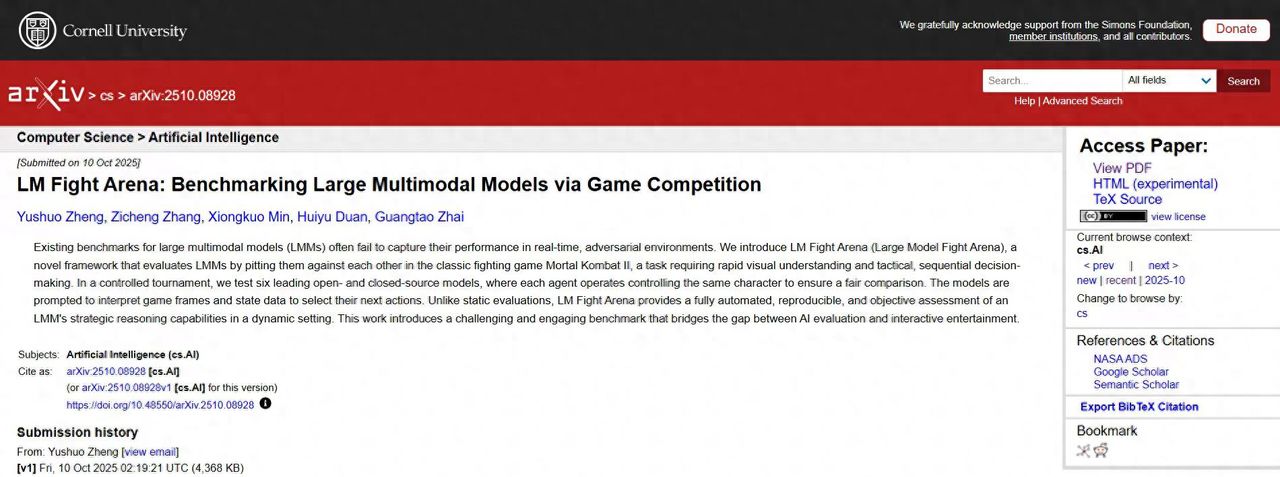
arxiv.org 最近的一篇论文,地址
https://www.arxiv.org/abs/2510.08928


把几种大模型AI扔进游戏厅,让它们在《真人快打II》的擂台上互殴——这就是这篇论文干的事儿!
以前评测多模态大模型(LMM),都是让它们看张图,然后回答“图里有几只猫?”这种问题。这太静态了,体现不出AI在动态、对抗性环境下的真实能力。该论文,搞个“大型模型格斗场”(LM Fight Arena),让六个顶尖的AI(包括开源和闭源的)在《真人快打II》里进行循环赛。它们都操控同一个角色(刘康),绝对公平。
比赛规则是看AI是怎么“看”和“动”的?
输入(AI的眼睛): AI会实时看到游戏画面和一些结构化的游戏状态数据(列如血条位置)。
输出(AI的手): AI需要根据看到的情况,用自然语言输出指令,列如“后退”、“发波”、“蹲防”。这些指令再被翻译成游戏手柄的按键。
比赛结果:谁才是“拳皇”?
冠军:Claude 3.5 Sonnet – 全胜战绩,血条优势也最大,堪称战术大师,攻防一体。
亚军:Gemini 2.5 Pro – 赢了80%的比赛,表现也很强势。
季军:Qwen2.5-VL-72B – 赢了60%,擅长“放风筝”(远程攻击)。
表现挣扎组: Qwen2.5-VL-32B 和 InternVL3-78B,时好时坏,战术不连贯。
“沙包”组:GPT-4o – 一场没赢! 论文里吐槽它“几乎不防守”,仿佛在说:“我看见了,但我就是不动!” 这和其他静态测试中GPT-4o的强势表现形成了巨大反差。
这篇论文用一个极其有趣的方式,提出了一个严肃且重大的观点:未来的AI评测,必须从“静态快照”走向“动态视频”。毕竟,真实世界就是一个充满不确定性和对抗的“大型格斗场”
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...