
ApacheDrill:一款开源的分布式SQL查询引擎
海量半结构化数据一秒变表格?我用ApacheDrill和Docker做了个现场实验,结果比预想更实用也更麻烦

最近公司要把各种日志、Mongo 导出、CSV 抓取到一起做临时分析,传统的ETL加数据仓库听着靠谱,但动辄几天甚至几周。说实话,我有点焦虑:临时问题就想临时看结果,谁有那么多耐心等数据工程把一切模式化。于是我周末用Docker 拉起了一个 Apache Drill 来试试,目标很简单:能不能用熟悉的 SQL直接查询半结构化文件,低延迟得出可用结论。结果比我想的要快,坑也不少,但总体可操作性让我不得不说服自己,这东西值得在临时分析场景纳入工具箱。
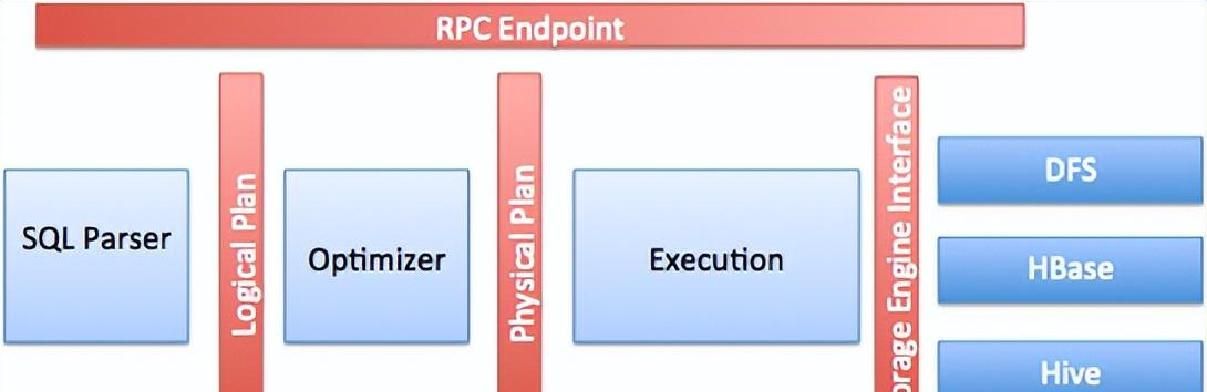
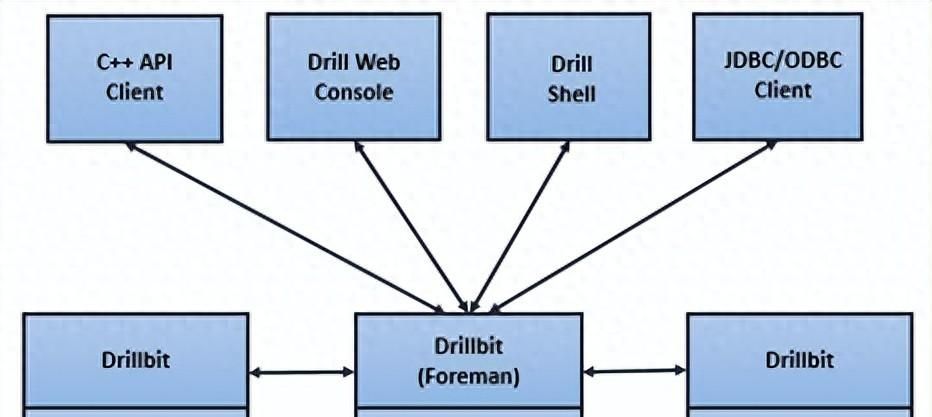
先说直观感受。Apache Drill 是一个开源的分布式 SQL查询引擎,专门擅长对半结构化数据做交互式分析。启动体验比想象中轻:用Docker 启动后,容器会自动进入 SQLLine 命令行,或者直接打开http://localhost:8047/ 就能看到 Web UI,敲一条类似 SELECT * FROMdfs.`/path/to/file.json` LIMIT 10 的语句,马上能把 JSON、CSV、Parquet等不同格式的数据读出来。不得不说,能用 SQL去联合多数据源,省掉了大量格式适配的工作,尤其对产品经理和分析师来说,上手门槛极低。

我朋友小李就是个实战例子。上个月他负责一个营销活动效果回溯,要把Mongo 的事件数据与 S3 上的广告投放 CSV联合分析。按常规是先做数据导出、清洗、入仓再分析,周期长且成本高。小李用了Drill,把 S3 注册成一个存储插件,直接在 SQL 中join,半小时内就验证出两个关键用户漏斗的差异,立刻给到运营改策。这个场景说明了Drill的价值:不是用来替代生产级数据仓库,而是快速临时探索、验证假设、节省时间成本的好工具。
但别被表面的方便迷惑,实际会遇到几个常见坑。第一是资源和内存管理,Drill基于 Java,默认内存配置在面对大文件扫描时会暴露短板,容器化部署时要给JVM 足够的堆和元空间,并合理分配 drillbit 节点的 CPU和内存。其次是格式选择,嵌套深且重复的 JSON直接全表扫描会很慢,我同事张姐当初直接把日志用原始 JSON扫描,查询卡得不行,后来把数据转换成 Parquet并加分区,性能立刻提升好几个数量级。再者是安全和权限,默认的 Drill对接存储时要注意访问控制和凭证管理,生产环境不能照搬本地实验的配置。
从技术选型角度思考,什么时候该用 Drill 而不是 Presto/Trino或云端分析服务呢?我看两类场景很合适:一类是临时性的多源联合查询,数据分散且不想做复杂ETL 时,Drill能用最少的工程量把数据拉来做探索;另一类是成本敏感的轻量交互分析,不想为查询频次低的数据长期付高额云仓库费用。相反,如果是长期稳定的高并发分析任务,或者需要复杂的安全审计、资源隔离和企业级管理能力,成熟的数仓或托管服务可能更合适。说白了,Drill的最佳定位是“按需探索型 SQL 引擎”,不是一键替代所有分析平台。
有些实操提议挺实用,值得直接拿去用。部署时尽量在容器里指定映射端口并挂载本地数据目录,这样方便调试和重启;连接外部存储先通过Web UI配置好存储插件并测试读取权限,避免连不上再去排查网络问题;对大表查询先试小样本,确认字段解析没问题后再扩展查询范围;遇到慢查询,优先思考把热点数据转为列式格式并分区,而不是盲目加节点。我的同事王工曾由于一次大表全表scan 耗尽了节点资源,后来我们总结出一个习惯:先做 LIMIT 1000的抽样,再基于抽样调整查询策略。
展望未来,半结构化数据只会越来越多,业务系统、日志和第三方数据源里充斥着JSON、嵌套数组和稀疏字段。趋势上我觉得会是“SQL继续往更多数据源延伸,计算引擎朝着更轻量和即插即用发展”。Apache Drill这类工具代表了一种思路:把分析的门槛下沉到数据工程之前,让业务快速验证方向。长期来看,结合数据网格和分布式文件层的演进,这类工具会在临时分析和数据探索阶段越来越常见,但要想成为企业级主力,还需要在安全、治理和监控上补足短板。
最后给出我启动实验环境的关键一步经验:用 Docker 快速搭一个本地Drill,打开 Web UI验证存储插件和小样本查询,遇到慢再思考转格式或加资源。官方文档和源码都很清楚,想深挖底层实现或贡献代码的人可以直接看仓库和上手指南。总体来说,Drill不是什么魔法,但它能在你最缺时间的时候,把复杂的数据“说”成你能听懂的表格,这一点很实用也很现实。
你有没有遇到过需要把分散在不同系统里的数据临时拼在一起分析的场景?说说你当时是怎么解决的,或者你最想把哪类数据用SQL 快速联查?我很想知道你的真实案例和遇到的具体问题。
来源:Apache Drill 官方文档
https://drill.apache.org/docs/getting-started/,官方代码仓库
https://github.com/apache/drill
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










