
阿里千问QWQ32b据说性能堪比DeepSeek R1671b版本,本电脑显卡RTX 3060,显存8G,本地部署没有问题。
一、本地安装ollama,请参考如下教程:
https://www.toutiao.com/article/7474957421350371891/?log_from=4a9f973decd148_1741424866088
二、进入网站https://ollama.com/library/qwq,查找千问QWQ32b模型。
1、进入网站输入qwq即可找到模型,如图 1;

图 1 搜索qwq,即可找到模型
2、复制安装命令,ollama run qwq,如图2。
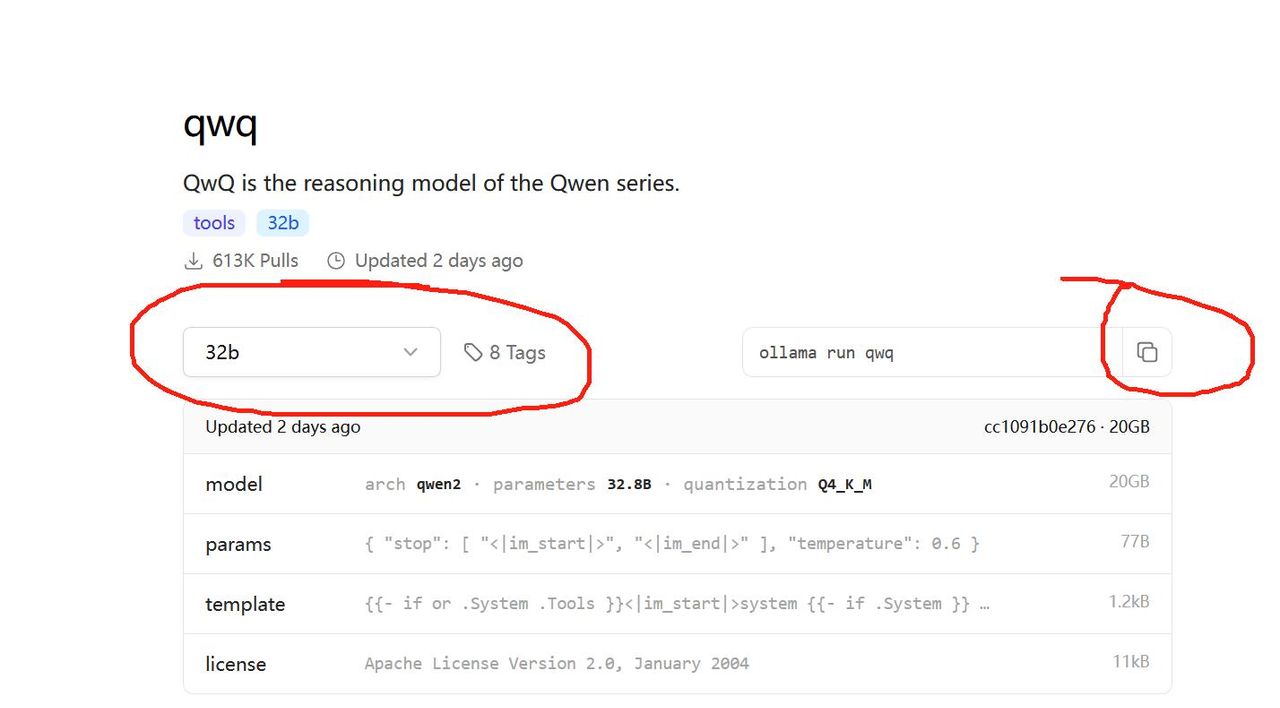
图 2 复制安装命令
三、在Ollama中部署千问QWQ32b模型。
1、在windows搜索框中搜索“windows Powershell”,然后以管理员身份运行 图 3;
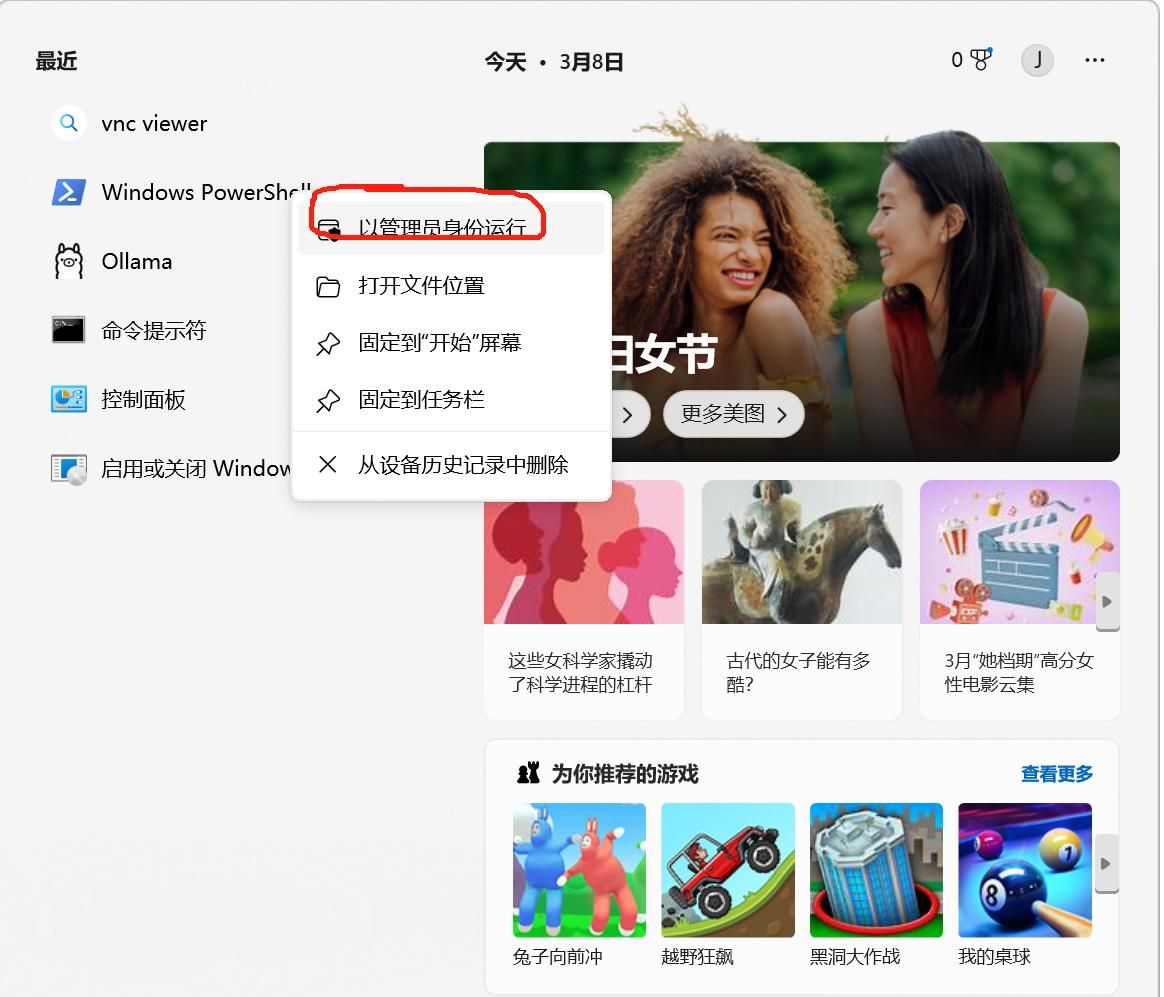
图 3 打开PowerShell
2、在windows Powershell中输入安装命令:ollama run qwq,点击enter开始下载(总共19 GB),等待下载、部署完成,图4、图5。
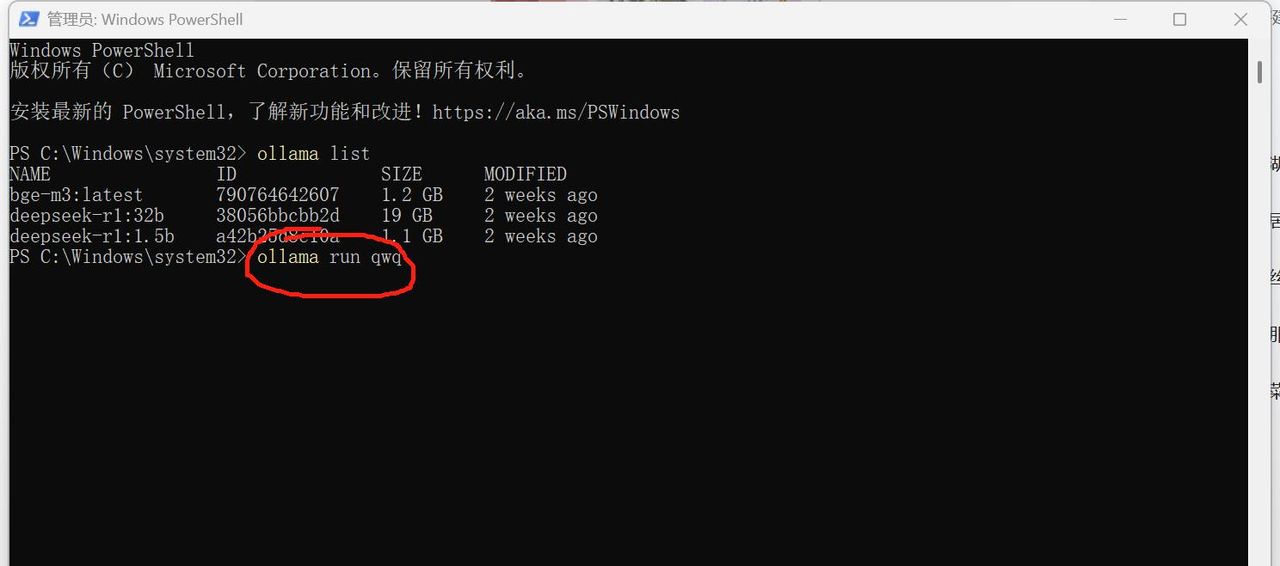
图 4 输入部署命令

图 5 部署好的qwen32b
四、在Cherry Studio中配置阿里千问QWQ32b。
1、在网站
https://cherry-ai.com/download下载CherryStudio安装程序,无脑安装,装好后如图 6;

图 6 安装好的Cherry Studio
2、打开Cherry Studio客户端,点击左下角“设置”>”模型服务”>”Ollama”,输入API地址为http://localhost:11434,然后点击>”管理”,选择需要添加的模型,列如qwq:latest或者deepseek-r1:32b 图 7;
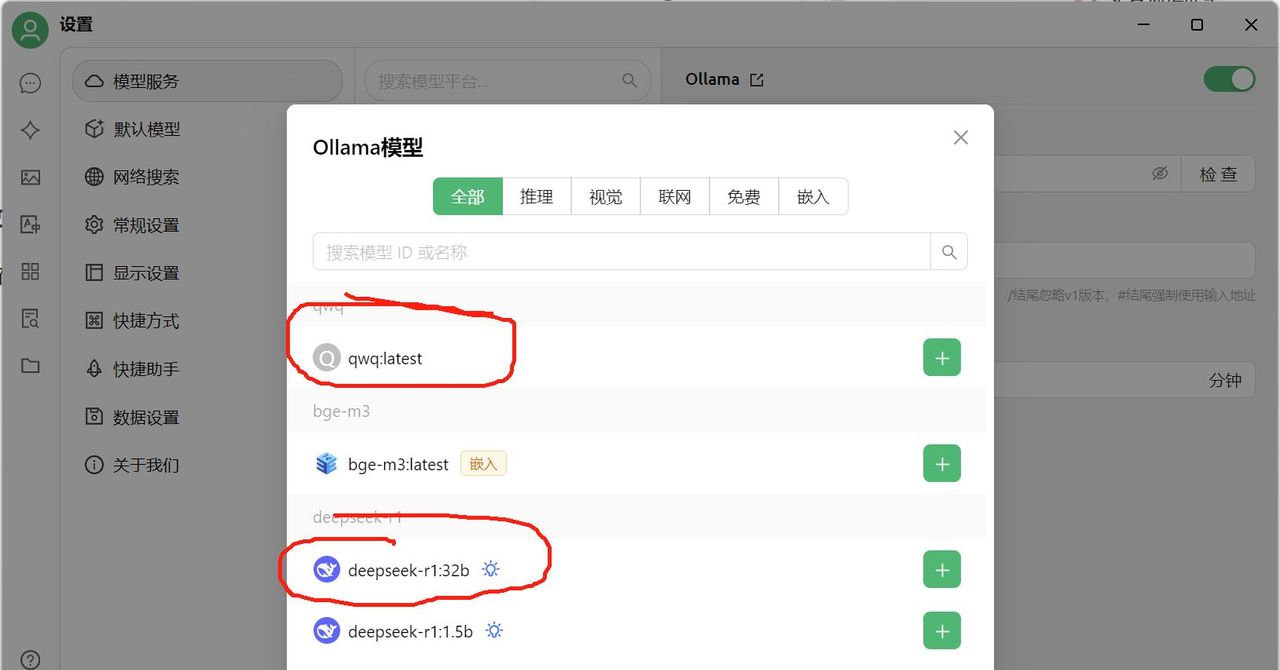
图 7 在Cherry Studio中设置模型
3、在Cherry Studio中添加助手“测试”图 8,在页面上方选择qwq32b大模型 图 9,测试一下成功图 10!接下来就尽情使用吧!无限Token!!
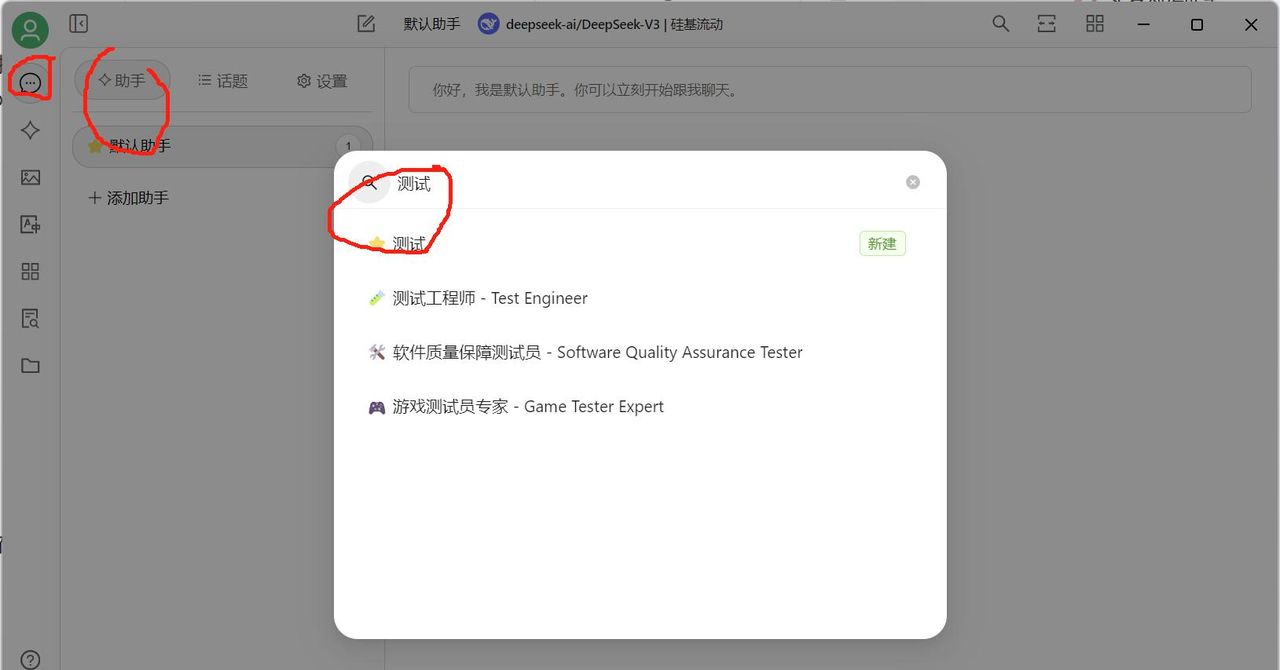
图 8 新建助手“测试”
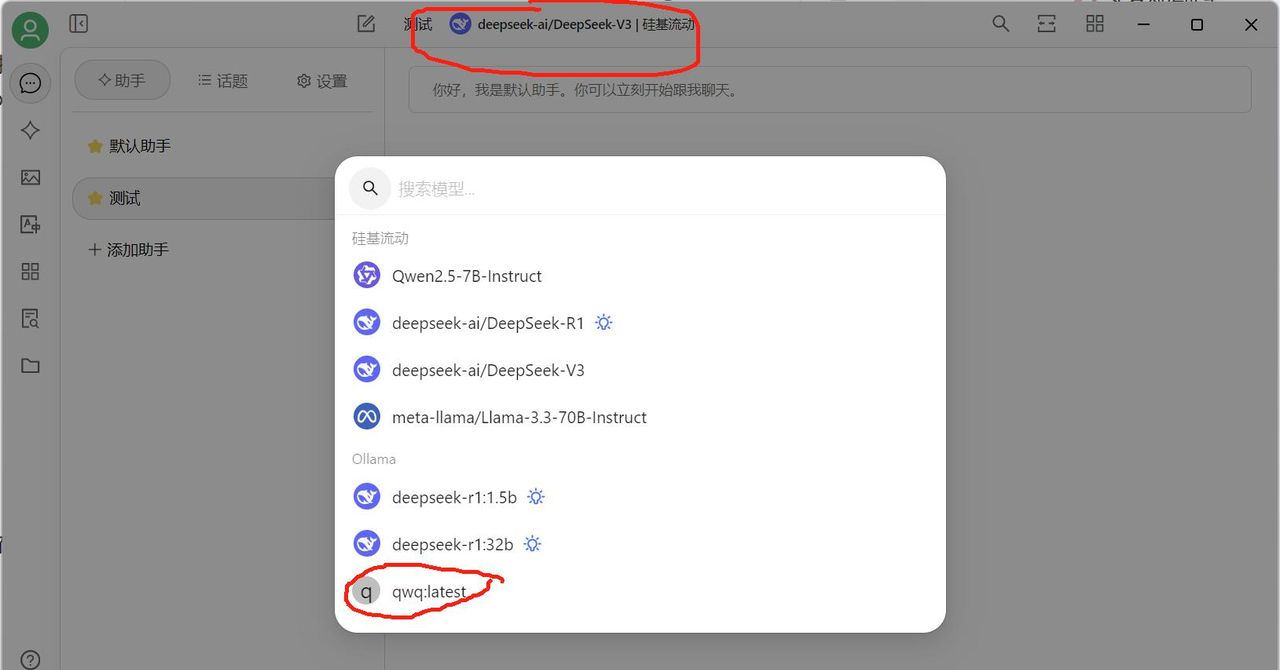
图 9 设置模型为qwq32b

图 10 测试qwq32b本地模型是否调用成功
写作不易,请加个关注,点个赞,感谢!
© 版权声明
文章版权归作者所有,未经允许请勿转载。














2060S试过CPU满载,内存拉爆,然后虚拟内存同样拉爆
已经测试过了,不太好用!耍小聪明,但是不听话。
要求不高的情况下还是可以用的
本地部署大模型,感觉自己变厉害啦。
收藏了,感谢分享