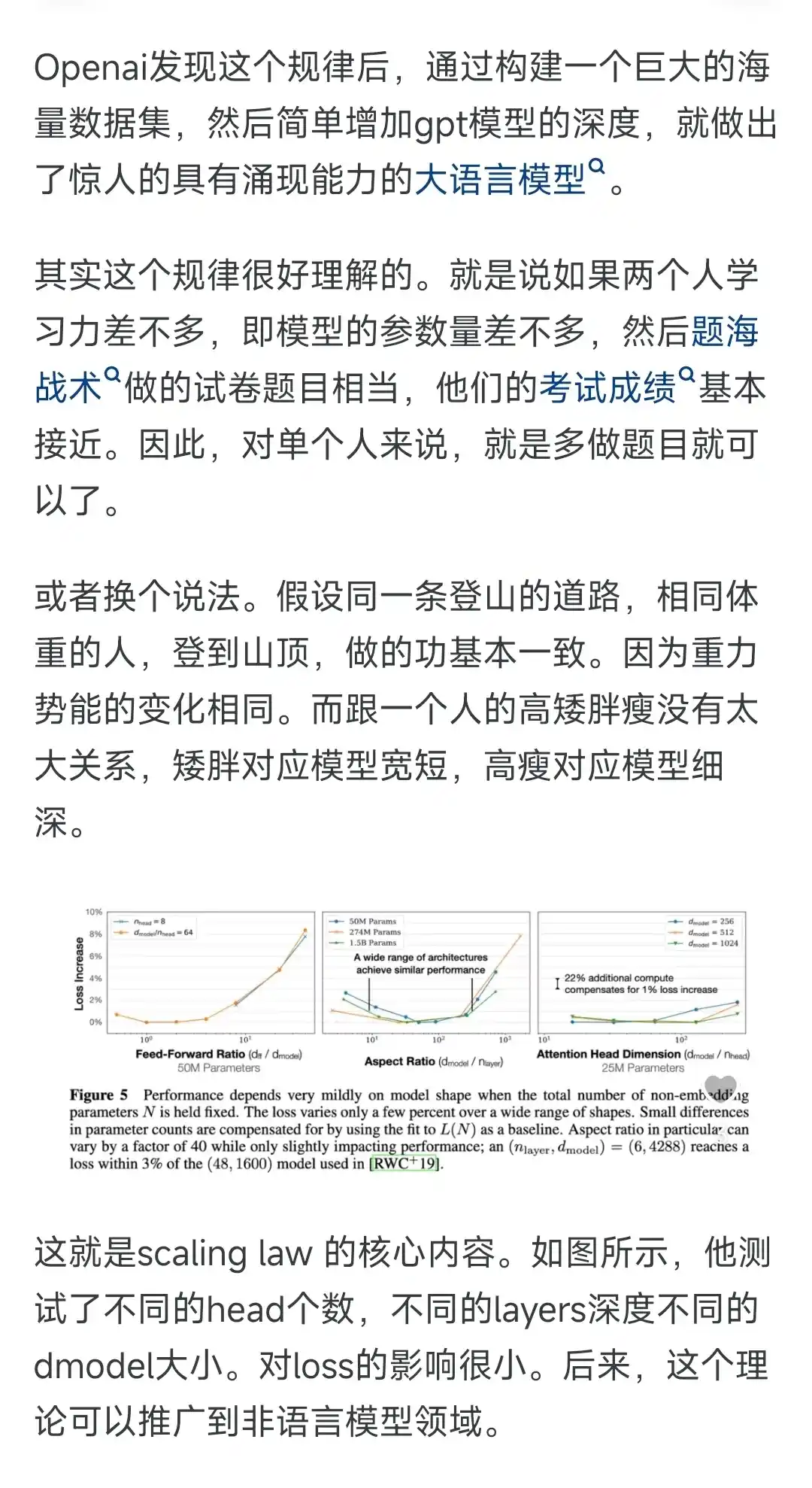
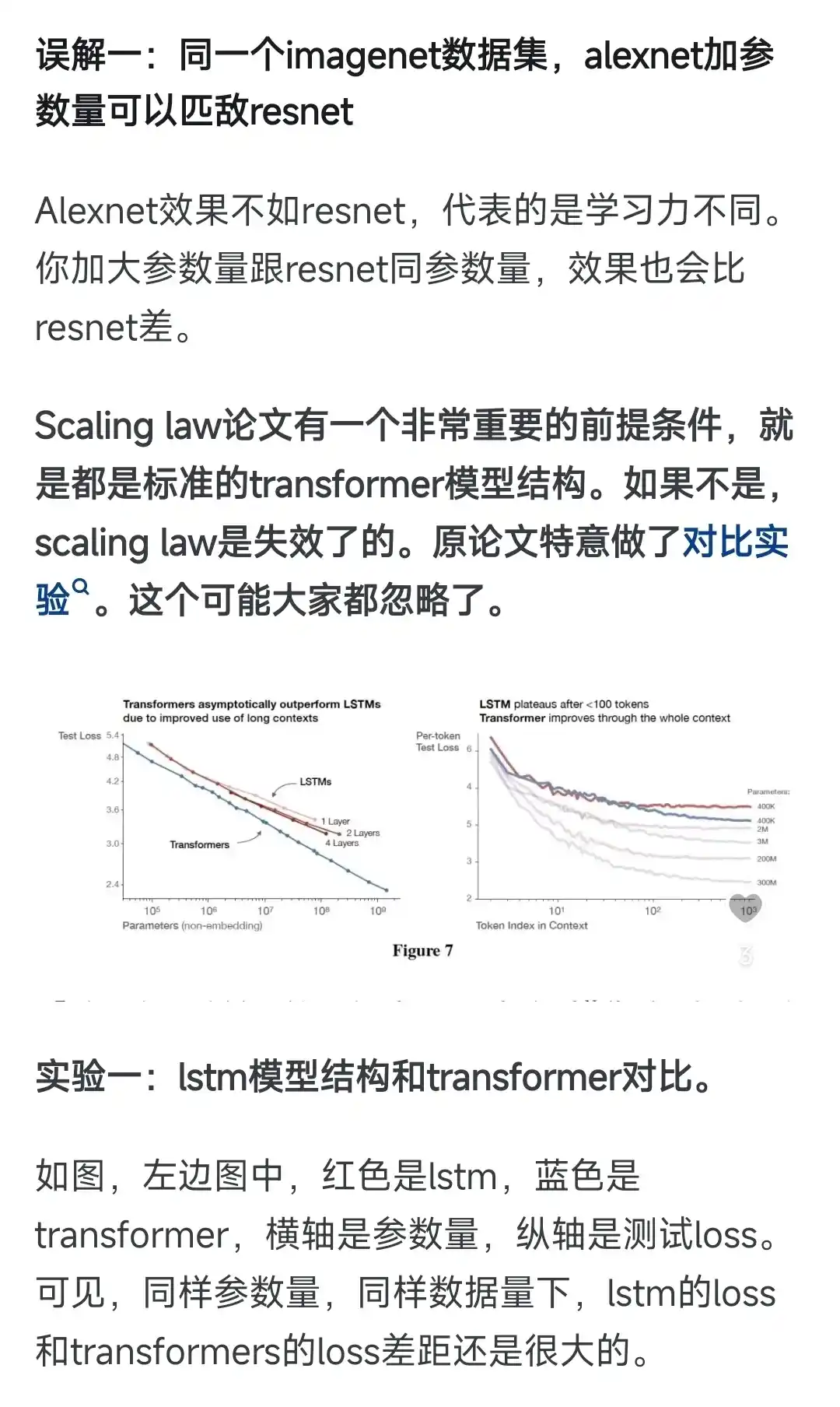


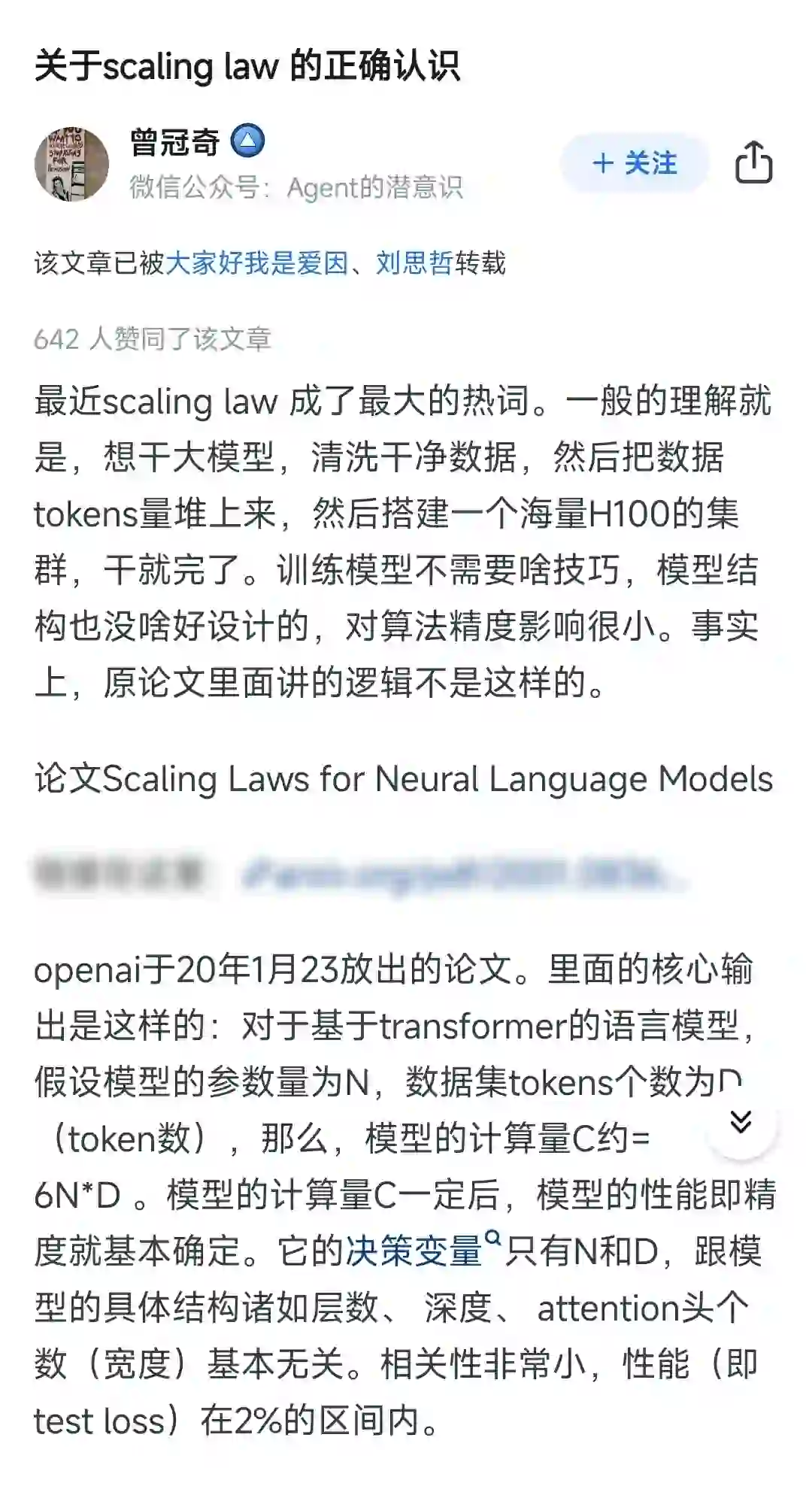
 最近scaling law 成了最大的热词。一般的理解就是,想干大模型,清洗干净数据,然后把数据tokens量堆上来,然后搭建一个海量H100的集群,干就完了。训练模型不需要啥技巧,模型结构也没啥好设计的,对算法精度影响很小。事实上,原论文里面讲的逻辑不是这样的。
最近scaling law 成了最大的热词。一般的理解就是,想干大模型,清洗干净数据,然后把数据tokens量堆上来,然后搭建一个海量H100的集群,干就完了。训练模型不需要啥技巧,模型结构也没啥好设计的,对算法精度影响很小。事实上,原论文里面讲的逻辑不是这样的。
论文Scaling Laws for Neural
实则这玩意想想也不科学,不用太迷信;列如我只有有1/10的data,我是不是可以构建一个10x大的模型来取得同样效果 反过来我data许多,model是不是可以做到人家几十分之一大小
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
没有相关内容!




我没想到这玩意还有论文(感觉没见过论文里scaling law标引用
就是这样啊